Risk Based Testing, Strategies for Prioritizing Tests against Deadlines
(리스크 기반 테스팅, 마감일에 맞추어 테스트 우선순위를 선정하기 위한 전략들)
Hans Schaefer, Software Test Consulting, hans.schaefer@ieee.org
http://home.c2i.net/schaefer/testing.html
종종 테스트 실행 이전의 모든 다른 활동들이 지연된다. 이것은 테스팅이 매우 심한 압력을 받으며 완료되어야 함을 의미한다. 그 일을 그만두거나, 출시 일정이 지연되거나 나쁘게 테스트 되거나 하는 것을 논외로 할때, 정답은 제한된 리소스를 가지고 최선의 가능한 일을 하기 위한 우선 순위 설정 전략이다.
시스템의 어떤 영역이 가장 많은 관심을 필요로할까? 특출난 대답은 없다. 그리고 무엇을 테스트 할 것인가에 대한 결정은 위험을 기반으로 해야 한다. 테스팅에 사용되는 리소스와 테스팅 이후의 리스크 간에는 관계가 있다. 단계별 릴리즈에 대한 가능성도 있다. 일반적인 전략은 다른 것들은 지연시키면서 릴리즈되었으면 하는 몇몇 중요한 기능들을 테스트 하는 것이다. (The general strategy is to test some important functions and features that hopefully can be released, while delaying others.)
첫째로, 누군가는 그 어플리케이션 내에서 가장 중요한 것을 테스트 해야 한다. 이것은 기능의 가시성, 사용 빈도, 실패시 발생하는 비용을 확인함으로써 결정할 수 있다. 둘째로, 누군가는 실패 가능성이 높은 부분을 테스트 해야 한다. 즉, 가장 문제가 되는 부분을 찾는 것이다. 이것은 제품 내에서 특히 결함 경향이 심한 (defect-prone) 영역을 확인함으로써 결정할 수 있다. 프로젝트 이력은 어떤 힌트를 제공할 수 있으며, 복잡도 같은 제품 측정치는 많은 힌트를 제공한다. 이 두가지를 사용해서 더 많이 테스트 해야 하는 영역과 덜 테스트 해야 하는 영역을 알아낼 수 있다.
테스트 실행이 시작되고 난 이후에, 몇개의 결함이 발견된다. 이 결함들은 아마도 re-focussing 테스팅의 근간이 될 것이다. 결함은 결함 경향이 심한 영역들에 서로 몰려있게 된다. 결함은 개발자들이 저지른 전형적인 실수들의 증상이다. 따라서, 하나의 결함은 더 많은 결함들이 근처에 존재한다는 추론을 가능케 한다. 그러므로, 동일 유형의 더 많은 결함들이 존재한다. 따라서, 테스트 실행의 후반부 동안에 누군가는 결함들이 어디에서 발견되었었는지 관심을 가져야 하며, 이전에 발견된 결함의 유형을 목표로 해서 더 많은 테스트를 만들어야 한다.
Disclaimer: 이 기고의 아이디어들은 안전 제일의 소프트웨어 (safety critical software)에서 사용되는 상황에서 검증되지 않았다. 이 아이디어들 중 일부는 그 영역에 적합할 수도 있으나, 충분한 고려가 필요하다. 여기에 제시된 아이디어들은 테스터가 리스크를 감당한다는 의미이며, 그 리스크는 심각한 실패로 현실화될 수도, 그렇지 않을 수도 있다.
소개
시나리오는 다음과 같다. 당신은 테스트 매니저이며, 당신이 테스팅에 대한 예산과 계획을 세웠다. 당신이 알고 있는 한도 내에서 당신의 계획은 합리적이며, 잘 짜여졌다. 테스트 계획을 실행할 시점이 되었을 때, 제품은 아직 준비 되지 않았고, 테스터들 또한 가용하지 않거나 예산이 방금 삭감되었다. 당신은 이러한 예산 삭감에 대해서 논쟁할 수도, 더 많은 시간이나 그게 무엇이든 간에 요구할 수 있다. 하지만, 그런 것들이 항상 도움이 되지는 않는다. 당신은 당신이 가진 더 적은 예산 더 짧은 시간을 가지고 일해야 한다. (일을) 그만 두는 것은 논쟁거리가 아니다. 당신은 일을 진행해야 할 뿐만 아니라 제품을 테스트 해야 한다. 그리고, 당신은 릴리즈 이후에도 무리없이 잘 작동하도록 만들어야 한다. 어떻게 하면 살아남을 수 있을까?
다양한 기법을 사용하고, 테스팅 프로세스의 여러 다른 측면을 공격하는 다양한 방법론이 존재한다. 이들중 일부는 제품 릴리즈 이전에 가능한한 많은 개수와 가능한 심각한 결함을 찾는 것에 목적이 있다. 이 기고의 다른 장에서 그 아이디어를 보일 것이다. 기고의 끝부분에서 어떤 아이디어가 제시되는데, 이것은 앞서 언급한 심한 압력의 시나리오를 방지하는데 도움이 될 것이다.
이 기고에서 우리는 상위 레벨의 테스팅에 대해서 이야기하고 있다. 즉, 통합, 시스템, 인수 테스트가 그것이다. 우리는 개발자들이 이미 모든 프로그램의 기본적인 수준의 테스팅을 수행해왔다고 가정한다 (유닛 테스팅). 또한 프로그램과 그 디자인이 어떤 식으로든 리뷰가 되어져왔다고 가정한다. 물론, 이 기고의 대부분의 아이디어들은 당신이 테스트 매니저를 맡기 이전에 아무것도 이루어져 있지 않더라도 가능하다. 하지만, 당신이 디자인/코드 리뷰나 유닛 테스팅 같은 앞단의 품질 제어 활동에서의 결과를 알고 있다면 더 손쉬워질 것이다. (It is, however, easier if you know some facts from earlier quality control activities such as design and code reviews and unit testing.)
1. 배드 게임
당신은 잃을 가능성이 아주 높은 게임을 하고 있다. 당신은 형편없는 테스팅을 하거나, 테스트하는데 더 많은 시간을 필요로 하게 되어 어쨌든 이 게임에서 질 것이다. 형편없는 테스팅을 한 이후에는 당신은 아마도 나쁜 품질에 대한 희생양이 될 것이다. 합리적인 테스팅을 한 이후에라도 당신은 늦은 릴리즈에 대해 책임을 질 것이다. 이러한 문제를 보여주는 좋은 시나리오는 Y2K 프로젝트이다. 마감일은 정해져 있었고, 테스팅은 아마도 마지막까지 진행되었을 것이다. 대부분의 경우, 디자인과 테스팅 동안에 문제가 발견되었고, 시스템의 소유자들은 문제가 발견된 것에 대해서 반겼을 것이다. 2000년 1월 1일에 아무런 나쁜 일도 일어나지 않았고, 이후 매니저들은 테스팅에 리소스가 낭비되었다고 결론내렸다. 하지만, 선택 가능한 옵션들이 있다. 이 기고를 통해 나는 Y2K 예제를 사용해 주요 이슈들을 보일 것이다.
어떻게 하면 이 게임에서 벗어날 수 있나?
당신에게는 창의적인 해결책이 필요하다. 말하자면 당신이 게임을 바꾸어야 하는 것이다. 당신은 당신이 가진 불가능한 책무에 대해서 경영진이 이해할 수 있는 방식으로 알려야 한다. 또 대안을 제시해야 한다. 그들에게는 출시할 수 있는 제품이 필요하지만, 또한 리스크를 이해해야할 필요도 있다.
한 가지 전략은 올바른 품질 수준을 찾는 것이다. 모든 제품이 무결점 (free of defects)일 필요는 없다. 모든 기능이 작동할 필요도 없다. 때때로 당신은 제품 품질을 낮추는 선택권도 가지고 있다. 이것은 당신이 덜 중요한 영역에 대해 테스팅을 줄이는 것을 의미한다.
또 다른 전략은 우선순위이다. 테스트는 먼저 가장 중요한 결함들을 찾아야 한다. 가장 중요하다는 것의 의미는 "가장 중요한 기능 중에서"라는 의미로, 이 기능들은 각각의 기능이 (제품이 의도된) 미션을 어떻게 지원하는지를 분석하고, 어떤 기능이 치명적인지 (critical) 또는 그렇지 않은지 점검해서 찾아낼 수 있다. 또한 당신은 많은 결함이 예상되는 곳을 더 많이 테스트 할 수 있다. 제품 내에서 가장 열악한 영역을 곧바로 찾고, 그들을 더 테스팅하면 더 많은 결함을 찾는데 도움이 될 것이다. 당신이 너무나 많은 심각한 문제들을 찾았다면, 경영진이 릴리즈를 연기하도록 자극되게 하거나, 당신에게 더 많은 시간과 리소스를 줄 것이다. 이 기고의 대부분의 내용은 가장 중요한 그리고 가장 열악한 영역의 우선순위 조합에 대한 것이 될 것이다.
세번째 전략은 일반적으로 테스팅을 더 값싸게 수행하도록 해준다. 여기서의 주요 이슈중 하나는 테스트 실행 자동화이다. 하지만 주의하라. 자동화는 특히 이전에 해보지 않았거나, 잘못 했던 경우에는 비용이 많이든다! 하지만, 경험이 있는 회사들은 수동 테스팅에 비해서 아무런 오버헤드 없이 테스트 실행 자동화를 할 수 있다.
네번째 전략은 누군가 다른 사람이 비용을 지불하도록 하는 것이다. 대개, 이 누군가 다른 사람은 고객이 된다. 당신은 문제가 많은 제품을 출시하고, 고객은 당신을 위해 결함을 찾는다. 많은 회사들이 이 방법을 적용하고 있다. 고객에게 있어 이러한 게임은 다른 대안이 없기 때문에 악몽과 같다. 하지만 이 전략이 장기간의 성공에 필요한 훌륭한 전략인지에 대해서는 논의의 여지가 있다. 따라서, 이 "다른 누군가"는 테스터가 아닌 개발자가 되어야 한다. 당신은 테스트를 수행하기 이전에 어떤 진입 조건 (certain entry criteria)을 만족하는 제품이 필요할 수도 있다. 진입 조건 (entry criteria)은 지속적으로 이루어진 어떤 형태의 리뷰, 유닛 테스팅에서의 최소한의 테스트 커버리지, 어느 정도의 신뢰성이 포함될 수 있다. (Entry criteria can include certain reviews having been done, a minimum level of test coverage in unit testing, and a certain level of reliability.) 문제는 이런 것들을 강제하도록 하기 위해서는 당신이 높은 수준의 지원을 받아야 한다는 점이다. 진입 조건은 프로젝트가 심한 압박을 받고 있거나 조직의 성숙도가 낮다면 무시되는 경향이 있다.
마지막 전략은 방지 (prevention)이다. 하지만, 이것은 테스트 매니저로서 당신이 프로젝트의 시작부터 참여하게 되는 다음번 프로젝트에서만 효과를 발휘한다.
2. 필요한 품질 수준 이해하기
소프트웨어는 거대하며, 복잡한 비즈니스 세상에 탑재된다. 품질은 그 맥락에서 고려되어야 한다 (8).
품질에 대한 무자비한 추구는 소프트웨어 제품의 기술적인 특성을 극적으로 향상시킬 수 있다. 어떤 어플리케이션들 - 의료 장치, 철도 신호 어플리케이션, 항공 네비게이션 시스템, 산업 자동화 그리고 군사 방어용 시스템 - 에서 필요로하는 특정 수준의 품질은 논의의 대상이 아니다. 하지만, 품질이 상업용 시장에서 전략적인 의사 결정을 할 때 가장 또는 유일하게 중요한 참고사항일까?
품질에 대한 고려는 기업의 장기간의 경쟁력과 재정적 상황에 가장 악영향을 끼치는 기본적인 이슈를 다루는데 적합하지 않다. 실제의 이슈는 어떤 품질이 최적의 재정적 성과를 낼 것인가 하는 문제다.
당신은 어떤 품질들과 어떤 기능들이 중요한지에 대해서 확신할 수 있어야 한다. 적은 결함이 항상 많은 이익을 의미하는 것은 아니다! 당신은 품질과 재정적 성과간에 어떤 관계가 있는 조사해야 한다. 그러한 연구의 예는 AT&T (9) 같은 회사에서 사용한 Return on Quality (ROQ) 컨셉이 해당된다. ROQ는 재정적인 성과를 향상시킬 수 있는 능력에 맞추어 미래의 품질 개선을 평가한다. 또한 가치 기반의 관리 (Value Based Management) 같은 방법론도 고려한다. 품질 그 자체를 광적으로 추구하는 것은 피한다. 따라서, 더 많은 테스팅이 항상 제품 성공에 필수조건은 아니다!
Y2K 문제의 예에서, 2000년 2월 29일에 제품의 동작이 실패할 것으로 받아들여졌을 지도 모른다. 또 19xx와 20xx의 날짜들이 뒤섞인다면, 레코드들이 잘못 소팅될 것이라 받아들여졌을 것이다. 하지만, 2000년 1월 1일 이후의 주문의 처리와 기록이 가능한 제품이 가장 크게 중요하다고 생각될 수도 있다.
3. 제품의 가장 중요하고 가장 취약한 부분에 대한 테스팅 우선순위
리스크는 제품에 의한 데미지와 데미지가 발생할 수 있는 가능성이다. 리스크를 평가하는 방법은 아래 그림 1에 설명되어 있다. 리스크 분석은 사용 중에 발생한 데미지, 사용 빈도를 평가하고, 결함 유입을 관찰해서 실패의 가능성을 판단한다.
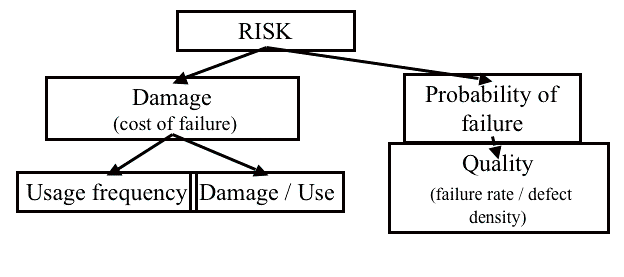
그림 1: 결함 정의와 구조 (Risk definition and structure)
테스팅은 항상 하나의 샘플이다. 당신은 결코 모든 것을 테스트할 수 없고, 항상 더 테스트 해야할 것들을 찾을 수 있다. 따라서, 당신은 항상 무엇을 테스트 해야 할지, 무엇을 테스트 하지 않아야 할지, 무엇을 더하고 덜해야 할지 결정해야 한다. 일반적인 목표는 가장 먼저 최악의 결함들을 찾는 것이다. 즉, 릴리즈 이전에 수정되어야 할 것들이며, 가능한 한 그런 결함을 많이 발견하는 것이다.
이것은 그 결함들이 반드시 중요해야 함을 의미한다. 대부분의 시스템적인 테스트 방법 (화이트 박스 테스팅, 동등 분할, 경계값 분석, 원인 결과 그래핑 같은)의 문제는 너무나 많은 테스트 케이스가 생성된다는 점이다. 이들 중 일부는 덜 중요하다 (17). 테스트 부하를 줄이는 방법은 가장 중요한 기능적 영역과 제품의 특성을 찾는 것이다. 가능한 한 많은 결함을 찾는 것은 제품의 취약한 영역을 더 테스팅해서 개선될 수 있다. 이것은 당신이 어디서 더 많은 결함이 예상되는지 알아야 함을 의미한다.
우리가 살펴본 모든 것들을 다룰 때, 그 결과는 항상 관련된 중요도를 가진 기능과 특성의 목록이 될 것이다. 최종 분석을 가능한 한 쉽게 하기 위해서 우리는 1 부터 5까지의 단계로 요소들을 표현할 것이다. 5점은 "가장 중요함" 또는 "가장 나쁨"에 부여하며, 대개 높은 리스크를 가지며, 더 많이 테스트하기 원하는 것이다. 1점은 덜 중요한 영역에 부여한다. (다른 출판물에서는 종종 1에서 3까지의 가중치를 사용한다).
상세 계산식은 이후에 제공한다.
3.1 데미지의 결정: 무엇이 중요한가?
당신은 테스트되어야 하는 영역에서 가능한 데미지가 발생한다는 사실을 알아야 한다. 이것은 제품의 가장 중요한 영역을 분석해야 함을 의미한다. 이 섹션에서는 이것을 우선순위화하는 방법을 살펴본다. 여기에 보여진 아이디어는 절대적으로 적절한 것은 아닐 수도 있다. 모든 제품에서 더 중요한 역할을 하는 요소가 존재할 수도 있다. 하지만, 여기에 제시된 요소들은 몇몇 프로젝트들에서 가치가 있었다.
중요한 영역은 기능들이나 기능 그룹일 수도 있고, 성능, 용량, 보안성 등의 특징일 수도 있다. 이러한 분석의 결과는 기능이나 특성 또는 관심이 필요한 그 둘의 조합의 목록이다. 나는 여기서 기능들을 더 중요하고 덜 중요한 영역들로 분류하는데 집중하고 있다. 하지만, 이 접근법은 유연하며, 다른 아이템들과 조정될 수 있다.
주요 기능들은 다음과 같다.
* 치명적인 (critical) 영역들 (실패의 결과나 실패의 비용)
당신은 전체적인 환경 내에서 그 소프트웨어의 사용형태를 분석해야 한다. 그 소프트웨어가 실패할 수 있는 방법을 분석한다. 그러한 실패 모드의 가능한 결과나 최소한 최악의 결과를 찾아본다. 여분의 백업 설비나 분석가나 오퍼레이터, 유저에 의해 소프트웨어 출력을 수동으로 체크할 수 있는 방법을 고려한다. 소프트웨어가 제어하는 하나의 프로세스에 직접 연결된 소프트웨어는 사용 전에 수동으로 출력이 리뷰되는 소프트웨어보다 더 치명적이다. 만일 소프트웨어가 하나의 프로세스를 제어한다면, 이 프로세스 그 자체가 분석되어야 한다. 그 프로세스 자체의 관성과 안정성은 어떤 형태의 실패를 만들어 낼 수도 있다.
예: 텔레콤 오퍼레이터를 위한 가입자 정보 시스템은 예를 들어, 가입 만료 일자로 31-12-99와 같은 애매한 숫자를 사용하는 경우 가입자 라인을 해지할 수도 있다. 이것은 치명적인 실패이다. 반면에, 리포트에서 년도 숫자는 2000년이 되면 공백으로 출력될 수도 있으나 이것은 작은 이슈이다.
작업 기간 동안에 즉시로 필요한 출력의 경우 몇 시간이나 며칠후에 전송될 수 있는 출력보다는 더 치명적이다. 반면에, 우편으로 대량의 데이터가 잘못 전송되는 경우, 우편 재발송 비용은 끔직한 수준이다. 데미지는 아래에 언급된 분류나 금전적인 가치로 정량화되거나 더 나은 무언가에 의해서 분류될 수 있다. 대규모의 다양한 데미지를 가진 시스템에서는 절대적인 금전적인 가치로 데미지를 사용하고, 더 하위의 그룹으로 분류하지 않는 것이 좋은 방법이다.
데미지의 그룹핑을 위해 가능한 계층 구조는 다음과 같다.
실패가 재난 수준인 경우 (3)
문제가 컴퓨터를 중단 시키거나, 심지어 환경에 크래쉬를 유발할 수도 있다 (전 국토나 비즈니스, 제품이 중지됨). 이러한 실패는 대규모의 재정적 손실을 다루어야 하며, 심지어 인명의 손실까지 초래한다. 예제에서도 특정 일자에 전화 네트워크의 모든 가입자가 대량 해지될 수도 있다.
실패로 인한 사업 면허 취소가 이런 유형에 속한다. 즉, 당국이 사업을 취소시킬 수도 있다. 심각한 법적인 결과가 또한 여기에 해당된다.
재난 수준의 실패의 마지막 종류는 인명에 위협이 되는 것이다.
실패가 데미지를 주는 경우 (2)
프로그램이 중단될 수도 있거나 데이터가 망실, 손상되고 프로그램이나 컴퓨터가 재시작 될때까지 기능이 작동하지 않는다. 예로는 12월 31일 한밤중쯤에 장비가 작동하지 않는 경우이다.
실패가 방해를 유발하는 경우 (1)
유저가 회피방법을 찾도록 강제되고, 동일 결과에 도달하기 위해 더 어려운 액션을 취해야 한다.
실패가 귀찮은 경우 (0)
문제가 기능에 악영향을 주지 않으나, 제품이 유저나 고객에게 덜 만족감을 준다. 하지만, 고객은 문제를 가지고도 일을 처리할 수 있다.
* 가시적인 영역들
가시적인 영역들은 무언가 잘못될 경우 많은 유저들이 실패를 경험하게 되는 영역이다. 유저에는 터미널에 앉아있는 오퍼레이터 뿐만 아니라, 리포트, 송장 또는 그 비슷한 것, 소프트웨어가 포함된 제품에 의해 제공받는 서비스에 의존적인 것들을 보는 최종 유저도 해당된다. 이 주제에 대해서 고려해야 하는 요인은 유저의 관용이다. 즉, 어떤 문제에 대한 그들의 참을성이다. 이것은 서로 다른 품질들의 중요성과 연관된다. 위를 보라.
훈련되지 않고 순진한 유저들을 위한 소프트웨어, 특히 공공 장소에서 사용되는 소프트웨어는 유저 인터페이스에 주의를 기울여야 한다. 강건성 (Robustness) 또한 주요 관심사가 된다. 하드웨어, 산업계의 프로세스, 네트워크 등과 직접 상호작용하는 소프트웨어는 하드웨어 실패, 노이즈 있는 데이터, 타이밍 문제 등의 외부적인 효과에 대해서 취약할 수 있다. 이런 종류의 소프트웨어는 환경이 변경되는 경우에 밸리데이션, 베리피케이션 그리고 재테스팅을 통과해야 한다.
가시적인 영역의 예는 전화를 걸게 해주는 전화 스위치의 기능이다. 덜 가시적인 영역은 전화 교환 같은 가치를 더해주는 모든 서비스이다.
가시성의 또 다른 요인은 고객의 신뢰성 상실 가능성이다. 즉, 고객이 회사의 제품을 구매하지 않기 때문에 장기간의 비즈니스 손실을 유발하는 장기간의 데미지이다.
* 사용 빈도
데미지는 얼마나 자주 기능이 사용되는지에 달려있다.
어떤 기능들은 매일 사용되며, 다른 기능들은 거의 사용되지 않는다. 어떤 기능들은 많은 사람에 의해 사용되며, 어떤 것들은 소수의 유저에 의해 사용된다. 자주 사용되는 기능에 우선순위를 부여한다. 하루에 발생하는 트랜잭션의 수는 우선순위를 찾는데 도움이 되는 아이디어이다.
몇몇 영역을 제외할 수 있는 여지는 좀처럼 사용되지 않을 것같은 기능을 제외하는 것이다. 즉, 분기, 반년에 또는 1년에 한번만 사용되는 것들이다. 어떤 기능들은 릴리즈 이후 최초 사용되기 전에 테스트될 수도 있다. Y2K 테스팅에서 가용한 전략은 2000년 1월과 2월의 윤년 기능을 테스트하고, 2000년 12월과 2004년 사이동안에 다시 테스트 하는 것이었다.
종종 이러한 분석이 명백하지 않기도 하다. 예를 들어, 프로세스 제어 시스템에서 몇몇 기능은 외부에서는 보이지 않을 수 있다. 현대의 객체 지향 시스템에서 많은 수의 중앙 라이브러리가 모든 곳에 사용될 수도 있다. 이렇게 되면 전체 시스템의 디자인을 분석하는 것이 도움이 될 수도 있다.
가능한 계층 구조는 다음과 같다. (3단계로)
피할 수 없음 (3)
대부분의 유저가 평균적인 사용 세션 동안에 접촉하게되는 제품의 영역 (예를 들면, 스타트업, 프린팅, 세이브).
자주 (2)
대부분의 유저들이 결국에는 접촉하게되는 제품의 영역, 하지만 모든 사용 세션 동안에 사용되는 것은 아니다.
가끔 (1)
평균적인 유저들이 결코 방문할 수 없는 제품의 영역, 하지만 고급 또는 경험있는 사용자들은 가끔 필요로하는 기능이다.
거의 없음 (0)
대부분의 유저가 결코 방문할 수 없는 제품의 영역, 이것은 아주 예외적인 액션을 통해서만 방문할 수 있다. 하지만, 치명적인 실패는 여전히 관심 대상이다.
중요한 요구사항을 선정하는 또 다른 방법은 (1)에 설명되어 있다.
중요성은 1 부터 5까지 단계를 사용해서 분류될 수 있다. 하지만, 어떤 경우 이것은 현실적으로 다양한 단계를 나타내기에 충분치 않다. 그래서, 데미지의 비용이나 실제 사용 빈도 같은 실제 수치를 사용하는 것이 좋다.
3.2 실패 가능성: 무엇이 가장 나쁜가 (추측하건데)
가장 나쁜 영역은 가장 많은 결함을 가진 영역이다. 과제는 어디에 가장 많은 결함들이 내재되어 있는지 추정하는 것이다. 이것은 가능성이 높은 결함 생성자 (defect generator)를 분석함으로 할 수 있다. 이 섹션에서는 가장 중요한 결함 생성자들의 일부와 결함 경향 영역이 보이는 증상을 설명한다. 많은 것들이 존재하는데, 당신은 여기서 언급한 것들 외에 본인들 만의 요인들을 항상 포함해야 한다.
* 복잡한 영역
복잡도는 아마 가장 중요한 결함 생성자일 것이다. 200개 이상의 서로 다른 복잡도 측정법이 존재한다. 20년 이상 복잡도와 결함 밀도의 관계에 대한 연구가 이루어져왔다. 하지만, 지금까지 어떤 예측 가능한 측정법도 유효하지 않다. 여전히, 대부분의 복잡도 측정은 문제가 많은 영역들을 나타낼 수 있다. 예로써는 긴 모듈, 많은 변수의 사용, 복잡한 로직, 복잡한 제어 구조, 거대한 데이터 흐름, 함수의 중앙 집중식 배치, 다단계 계층구조 트리, 그리고 디자이너에 의해서 이해되는 주관적인 복잡도들이 해당된다. 이것은 당신이 복잡도의 여러 측면에 기반하여 다수의 복잡도 분석을 해야하며, 문제를 내포할 수 있는 제품의 서로 다른 영역을 찾아야 함을 의미한다.
* 변경된 영역
변경은 중요한 결함 생성자이다 (13). 한 가지 이유는 변경은 주관적으로 이해되기 쉬우며, 따라서 그 영향력을 (impact)을 충분히 분석하지 않는다는 것이다. 또 다른 이유는 변경이 시간적인 압박하에서, 분석이 완전히 완료되지 않은 채로 이루어진다는 점이다. 그 결과는 사이드이펙트 (sideeffects) 이다. 클린룸 프로세스 (Cleanroom process) 같은 현대의 시스템 디자인 방법론의 지지자들은 유닛 테스트에서의 디버깅은 품질에 도움이 되기 보다는 방해가 된다고 주장한다. 왜냐하면, 그들이 수정하는 것보다 더 많은 결함이 유입되기 때문이다.
일반적으로 변경 완료에 대한 약속이 존재해야 한다. 이것은 형상 관리 시스템 (그와 유사한 것)의 일부분이다. 당신은 변경들을 기능적인 영역별로 또는 다른 것으로 분류할 수 있고, 예외적으로 변경이 많은 영역을 찾을 수 있다. 이런 상황은 이전부터 디자인이 좋지 못했거나, 나쁜 디자인 이후에 최초 디자인이 수많은 변경에 의해 파괴되어 온 것일 수 있다.
또한 수많은 변경은 나쁘게 이루어진 분석의 증상이기도 하다 (5). 따라서, 과도하게 변경된 영역은 유저의 기대와 일치하지 않을 수도 있다.
* 새로운 기술, 솔루션, 방법론의 영향력
프로그래머들은 학습 곡선 (learning curve) 을 경험하는 새로운 툴, 방법론 그리고 기술을 사용한다. 초기에 그들이 익숙해질 때까지는 많은 결함을 만들어낼 수 있다. CASE 툴 같은 툴들이 회사에 새로 도입되거나 시장에 최초로 등장할 때는 다소간 불안정할 수 있다. 또 다른 이슈는 프로그래머에게 새로 도입되는 프로그래밍 언어나 GUI 라이브러리이다. 어떤 새로운 툴이나 기법도 문제를 야기할 수 있다. 좋은 예는 새로운 유형의 유저 인터페이스를 가진 최초 프로젝트이다. 일반적인 기능은 잘 작동할 수 있으나, 유저 인터페이스 서브시스템은 문제 투성이가 될 수 있다.
또 다른 고려해야 할 요인은 방법론과 모델의 성숙도이다. 성숙도는 이론적인 기반이나 경험적인 흔적의 힘을 의미한다 (Maturity means the strength of the theoretical basis or the empirical evidence.) 만일 소프트웨어가 유한 상태 기계 (finite state machines), 문법, 관계형 데이터 모델 같은 기존에 이미 수립되어 있는 방법을 사용한다면, 해결해야 하는 문제는 그러한 모델에 의해서 적절히 표현할 수 있어, 그 소프트웨어는 매우 안정적일 것으로 기대할 수 있다. 반면에, 방법론이나 모델이 새롭고 증명이 되지 않은 것이거나, 사용하는데 신기에 가까운 기술 (state of the art)을 요구한다면, 그 소프트웨어는 매우 불안정해질 수 있다.
대부분의 소프트웨어 비용 모델들은 방법론, 툴, 기술을 프로그래머의 경험에 맞추는 요소를 포함시킨다. 이것은 테스트 계획에 중요하며, 또 비용 추산에도 중요하다.
* 참여한 인원의 수에 의한 영향
여기에서의 아이디어는 1000마리 원숭이 신드롬이다. 한 작업에 많은 수의 사람이 참여할 수록, 의사소통에 더 큰 오버헤드가 생기고, 일이 잘못될 가능성이 높아진다. 숙련된 소수의 인력은 평균적인 수준의 능력을 가진 큰 그룹보다 더 생산적이다. (A small group of highly skilled staff is much more productive than a large group of average qualification.) COCOMO (10) 소프트웨어 비용 모델에서, 이것은 소프트웨어 크기 다음으로 가장 큰 요인이다. 이 영향력의 많은 부분은 결함을 발견하고 수정하는데 들어가는 effort로 설명될 수 있다.
상대적으로 숙련된 인력과 덜 숙련된 인력이 함께 배치된 영역은 더 훌륭한 테스팅이 필요한 영역이기도 하다.
이러한 분석을 할 때 심사숙고해야 한다. 어떤 회사에서는 (11) 가장 복잡한 영역에 최고의 인력을 투입하고, 쉬운 영역에 덜 숙련된 인력을 배치한다. 그러면, 결함 밀도는 인력의 숙련도와 참여한 인력의 수를 반영하지 않을 수도 있다. (Then, defect density may not reflect the number of people or their qualification.)
전형적인 케이스는 철저한 후속조치 없이 고용된 다수의 컨설턴트에 의해 개발된 프로그램이다. 그들은 각자 서로 완전히 다른 방식으로 작업한다. 테스팅 동안에 아마도 모든 사람이 서로 다른 날짜 포맷, 서로 다른 시간 윈도우를 사용하고 있는 것을 발견하게 될 것이다.
* 인력 교체의 영향
만일 인력이 그만둔다면, 새로운 인력이 그 일을 계속할 수 있기까지 디자인 제약사항을 배워야 한다. 모든 것이 문서화되어 있지 않다면, 몇몇 제약사항들은 신규 인력에게는 알려지지 않아 결함의 원인이 된다. 사람들 사이를 (작업으로) 중첩하는 것은 바람직하지 않다. 일반적으로, 인력이 교체된 영역은 동일 그룹의 인력으로 전체 작업을 완료한 영역보다 더 많은 결함을 보인다.
* 시간적 압박의 영향
시간적 압박은 사람들이 꽁수 (short-cuts)를 쓰도록 한다. 사람들은 점점더 작업을 완료하려고 집중한다. 그리고 종종 품질 제어 활동을 건너뛰며, 모든 것이 잘 될 것이라고 낙관적으로 생각한다. 성숙한 조직에서만 이러한 낙관론이 제어되는 것처럼 보인다.
또한 시간적인 압박은 오버타임 작업을 하도록 한다. 하지만, 연장 근무 기간에 사람들의 집중력이 저하된다는 것은 잘 알려져있다. 이것은 더 많은 것의 원인이 된다. 리뷰와 인스펙션의 적용에 있어 꽁수를 부리게 되어 결함 밀도를 극심한 수준까지 이끌수도 있다.
개발 기간 동안에 일어나는 시간적인 압박에 대한 데이터는 시간 목록, 프로젝트 미팅 시간을 연구하거나 관리자나 프로그래머와의 인터뷰를 통해서 잘 발견된다.
* 최적화가 필요한 영역
COCOMO 비용 모델은 비용 발생 요인중 하나로 장비의 부족과 네트워크 용량과 메모리를 언급한다. 문제는 최적화가 추가적인 디자인 노력을 필요로 하거나, 덜 강건한 (robust) 디자인 방법을 사용해서 작업될 수 있다는 점이다. 추가적인 디자인 노력은 결함 제거 활동으로 부터 리소스를 빼앗아 가며, 덜 강건한 디자인 방법은 더 많은 결함을 만들어 낼 수 있다.
* 이전에 많은 결함이 존재했던 영역들
결함 수정은 새로운 결함을 유도하는 변화를 만들어 낸다. 그리고 결함 경향이 있는 영역은 되풀이되는 경향이 있다. 리뷰나 유닛 그리고 서브시스템 테스팅에서 결함 경향이 있었던 영역이 시스템이 고객에게 전달되고 난 이후에도 결함 경향이 있는 영역이었다는 경험이 많다. (5)과 (7)의 연구에서 보이듯이 과거에 결함이 있었던 모듈은 미래에도 결함을 가질 가능성을 보인다. 만일 디자인과 코드 리뷰에서의 결함 통계 그리고 유닛과 서브시스템 테스팅의 통계가 존재한다면, 이후 테스트 단계를 위해 우선순위가 정해질 수 있다.
* 지리적인 분산
만일 한 프로젝트에서 함께 작업하는 사람들이 지리적으로 함께 하지 않는다면, 커뮤니케이션은 나빠질 것이다. 이것은 국지적 영역에 있더라도 사실이다. 여기에 위치가 프로젝트에 악영향을 줄 수 있는지 아닌지 평가하는데 도움된다고 증명된 아이디어들을 제시하겠다.
o 같은 건물 내에 서로 다른 층의 사무실에서 일하는 사람들은 동일 층에 위치하는 사람들만큼 잘 의사소통하지 못한다.
o 25미터 이상 떨어져 앉아있는 사람들은 충분히 의사소통하지 못한다.
o 작 업 공간 내에 공용 공간, 즉 공용 프린터나 커피 머신은 의사 소통을 개선해 준다. 서로 다른 건물에 앉아있는 사람들은 같은 건물에 있는 사람들만큼 의사소통 하지 않는다. 서로 다른 랩에 앉아있는 사람들은 같은 랩에 있는 사람보다 덜 의사소통한다. 서로 다른 국가에서 온 사람들은 문화적으로나 언어적으로 어려움을 겪을 수 있다. 만일 사람들이 서로 다른 시간대에 거주한다면, 의사 소통은 훨씬 더 어려울 것이다. 이것은 소프트웨어 개발 아웃소싱에서의 문제이다.
이론적으로, 지리적인 분산은 위험하지 않다. 위험은 예를 들어, 시스템의 공통 부분에 대해서 그들이 작업할 때, 거리가 떨어져 있는 사람들이 의사소통을 해야할 때 발생한다. 당신은 해당 소프트웨어 구조가 사람들간에 훌륭한 커뮤니케이션을 필요로 하지만, 이 인력들이 지리적으로 떨어져 있는 영역을 찾아내야 한다.
* 이전 사용 이력
만일 이전에 많은 유저들이 소프트웨어를 사용해왔다면, 활발한 유저 그룹은 새 버전을 테스팅하는데 도움이 될 수 있다. 베타 테스팅도 가능할 것이다. 완전히 새로운 시스템에 대해서는 유저 그룹이 정의될 필요가 있고, 프로토타이핑이 적용되어야 한다. 대개 완전히 새로운 기능 영역들은 요구사항이 잘 알려져 있지 않기 때문에 대단히 결함 경향이 많다.
* 내부적 요인
이러한 예에는 그 일을 이미 했던 사람을 찾거나, 다른 사람과 잘 의사소통하지 못하는 사람을 찾거나, 프로젝트에 새로 유입된 사람, 최근에 편성된 조직, 서로 간에 갈등이 있는 매니저들을 찾아 보는 것과 명성과 다른 많은 요인들이 포함된다. 기발한 생각만이 내부적인 요인들을 잘 구별하게 해준다. 메시지는 다음과 같다. 당신은 여기서 논의되어진 요인들 외에 가능한 외부적인 요인에 대해서 주의해야 한다.
* 고려되어야 하는 하나의 일반적인 요인
이 기고는 하이 레벨 테스팅에 대한 것이다. 이것 이전에 개발자들이 테스트를 한다. 개발자들이 이전에 그 소프트웨어를 어떻게 테스트 했었는지 살펴보고, 일반적으로 그들이 간과한 문제의 유형이 무엇인지 살펴보는 것이 합리적이다. 유닛 테스트의 품질을 분석하라. 이것은 테스트 케이스 선택 방법 (17)을 더욱 맞춤식으로 할 수 있도록 해준다.
이러한 요소들을 살피는 것은 테스트되어야 할 영역의 결함 밀도를 결정할 수 있다. 하지만, 이것만을 사용해서는 일반적으로 몇몇 영역에 과도하게 높은 수치를 부여하게 된다. 대개 거대한 컴포넌트는 테스트 해야 할 것들이 많다. 따라서, 수정 요소 (correction factor)가 적용되어야 하는데, 이것은 테스트되어야 할 영역의 기능적인 크기이다. 말하자면, 이 영역의 전체 가중치는 "결함 경향성 / 기능적인 볼륨"이 될 것이다. 이 요소는 초기 기능 점수 분석 (function point analysis)이나, 가능하다면 코드 라인수 카운트에서 발견될 수 있다.
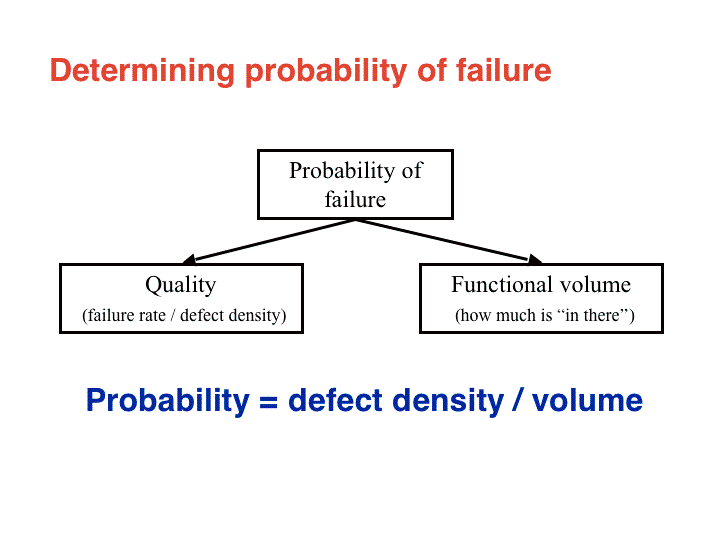
그림 2: 실패 가능성 (Failure Probability)
당신이 그 프로젝트에 대해서 아무것도 알지 못하며, 모든 결함 생성자가 적용될 수 없다면 무얼 해야 하나?
테스트를 해야 한다. 먼저 러프 테스트를 통해 결함 경향이 있는 영역을 찾고, 다음 테스트는 그것들에 집중한다. 첫번째 테스트는 전체 시스템을 모두 커버해야 하나, 너무나 얕은 수준이 되어서는 안 된다. 이 테스트는 전형적인 비즈니스 시나리오만을 커버하고, 몇몇 중요한 실패 상황을 다루어야 하지만 전체 시스템을 커버하지는 않아야 한다. (It should only cover typical business scenarios and a few important failure situations, but cover all of the system.) 그런 다음, 가장 문제가 많은 영역을 찾고, 다음 번 테스팅 차수에 그 영역에 우선순위를 준다. 그 다음번 차수는 우선순위가 정해진 영역에 대해서 깊고 철저하게 테스팅한다. 이 두 단계의 접근법은 항상 적용될 수 있다. 테스팅 이전에 우선순위를 정하고 계획을 세우는 것 이외에도 이 두 단계의 접근법은 항상 적용될 수 있다. 4장에서 좀더 설명한다.
3.3 테스트 영역의 우선순위를 어떻게 계산하나?
일반적인 방법은 가중치를 부여하여 시스템의 모든 영역에 대한 가중치의 합계를 계산하는 것이다. 결과값이 가장 높은 것을 테스트한다! 모든 요소를 선정하고 상대적인 가중치를 할당한다. 당신은 이것을 매우 공을 들여해야 한다. 하지만, 이 작업은 매우 많은 시간을 소모하게 될 것이다. 대개의 경우 3개의 가중치로 충분하다. 1, 3, 10의 값을 정한다. ("아주 중요하지 않은 요인"에는 1, "중간정도의 영향력을 미치는 요인"에는 3, "아주 강한 영향력을 미치는 요인"에는 10).
모든 요인이 선정되었다면, 모든 제품 요구사항 (모든 기능, 기능적인 영역 또는 품질 특성)에 숫자를 부여한다. 더 중요한 요구사항이나 그 영역 내에서 결함 생성자로 보이는 것에는 더 많은 수치를 부여한다. 대개 1에서 3 또는 5까지의 단계가 충분하다. 숫자 부여는 직관적으로 수행될 수 있다.
한 요인에 부여하는 숫자는 그 자체의 가중치와 곱해진다. 이것은 1과 50 사이의 가중치가 부여된 숫자를 만들어 낸다. 이 가중치가 부여된 숫자들은 이후 데미지 (impact)와 에러 가능성과 더해져서 최종적으로는 곱해진다. 현실적으로 많은 직관적인 매핑이 로그급수로 늘어나는 모양을 보이기 때문에, 숫자들은 10의 곱의 모양을 따른다. 그러므로, 관련된 리스크 계산은 가능성과 데미지의 가중치 부여된 합이 계산된 것을 더해야 한다. 만일 대부분 요인의 점수들이 본질적으로 직선형을 따른다면, 리스크 계산은 가능성과 데미지 점수를 곱해야 한다. 이 방법을 사용하는 유저는 그들이 이 방법을 어떻게 사용할 것인지 정해야 한다! 이후에 가장 점수가 높은 영역에 대해서 가장 많은 테스트를 할당하는 계획이 세워진다.
예제 (서로 다른 영역의 기능적인 볼륨은 같다고 가정)
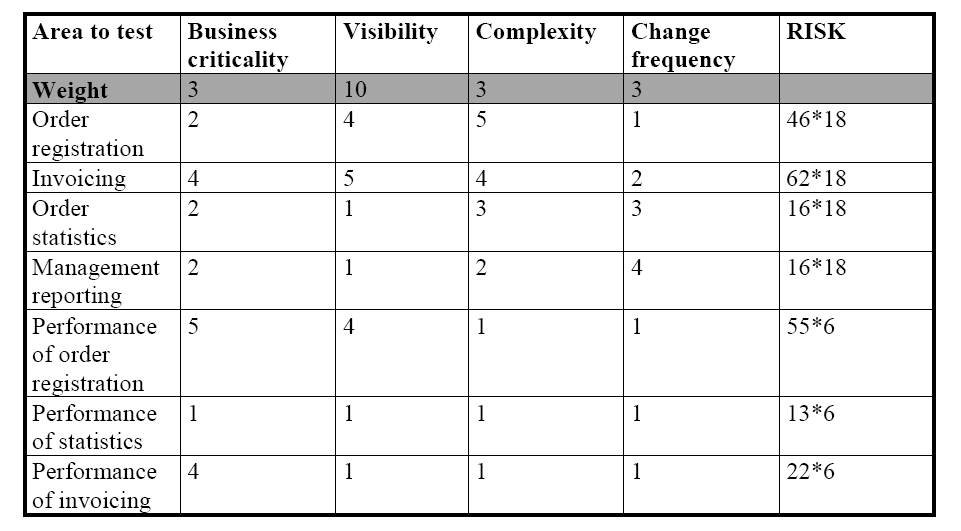
이 테이블은 "송장" 기능이 테스트 해야할 가장 중요한 기능이라고 제안하며, "주문 등록"과 주문 등록의 성능이 그 다음이다. 가장 중요한 것으로 선정된 요인은 가시성이다.
계산은 스프레드시트를 사용해서 프로그램될 수 있으므로 쉽다. 더 상세한 케이스 연구는 (4)를 참고하라. 스프레드시트는 http://home.c2i.net/schaefer/testing/riskcalc.hqx에서 얻을 수 있다. (Binhex file 파일이므로 저장하고, 압축해제해서 엑셀에서 오픈하라)
경고: 점수 할당은 직관적이므로 잘못되었을 수 있다. 따라서, 점수는 대강의 가이드라인으로의 의미만 있다. 중간과 낮은 리스크 영역과 높은 리스크 영역은 충분히 구별되어야 한다. 이것이 이 작업의 주요 책무이다. 또한 이것은 원래 목적에 필요한 것보다 더 정밀할 필요는 없다. 만일 더 정밀한 테스트 우선순위가 필요하다면, 더 수량적인 접근법이 사용되어야 한다. 특히 가능한 데미지는 그 자체의 절대값으로 사용되어야 하며, 점수로 변환되어서는 안 된다. 이 접근법은 (18)에 설명되어 있다.
4. 테스팅을 더 효과적으로 만들기
더욱 효과적인 테스트란 동일 시간안에 더 중요한 결함들을 찾는 것을 의미한다. 이것을 달성하기 위한 전략은 과거의 경험에서 배우고 테스팅에 적용하는 것이다.
먼저, 전체 테스트를 4개의 단계로 세분화해야 한다.
. test preparation
. pre-test
. main test
. after-test.
테스트 준비 (test preparation)는 테스트 할 영역, 테스트 케이스, 테스트 프로그램, 데이터베이스와 전체 테스트 환경을 준비한다. 특히, 테스트 환경에 대한 준비는 문제와 지연이 많을 수 있다. 일반적으로 프로그램 그 자체를 올바른 시스템과 데이터베이스 시스템에 인스톨하는 것은 쉽다. 문제는 종종 미들웨어에서 발생한다. 말하자면, 클라이언트가 동작하는 소프트웨어 간의 연결, 그리고 서로 다른 서버 상에서 동작하는 소프트웨어가 해당된다. 테스트 환경의 모든 측면을 충분히 구체화하는데 주의를 기울여야 하며, 테스트가 적시에 수행될 수 있도록 하기 위해 시운전 (dry runs)이 필요하다. Y2K 프로젝트에서, 1999년 이후의 머신 날짜에서 라이센스가 올바른지 확인하고, 라이센스가 머신 날짜의 재설정을 가능하게 하는지에 집중했었다. 집중한 또 다른 영역은 소프트웨어가 Y2K 호환이 되는지 였다.
프리 테스트 (pre-test)는 테스트 중인 소프트웨어가 테스트 랩에 설치되고 난 이후에 수행된다. 이 테스트는 일상적인 사용 시나리오를 구동하는 몇개의 테스트 케이스로 구성된다. 목표는 소프트웨어 전체가 테스팅 되기에 적합한지 또는 완전히 믿을 수 없는지, 불완전하게 설치되었는지 확인하기 위한 테스트이다. 또 다른 목표는 초기 품질 데이터를 확보하는 것으로, 이러한 데이터에는 이후 테스트를 지속하면서 집중해야 하는 결함 경향이 있는 영역을 찾는 것이다.
메인 테스트 (main test)는 사전 정의된 테스트 케이스 전체로 구성된다. 이들이 실행되면서 실패들이 기록되고, 발견된 결함이 수정된다. 그리고 테스트 랩에 새로운 소프트웨어가 설치된다. 모든 신규 설치에는 새로운 프리 테스트가 포함된다. 메인 테스트는 테스트 실행 프로젝트 동안에 대부분의 시간을 소모한다.
애프터 테스트 (after-test)는 매 소프트웨어 신규 릴리즈를 가지고 시작한다. 이것은 최적화가 발생해야 하는 단계이다. 애프터 테스트의 일부분은 리그레션 테스팅으로, 결함 수정의 사이드이펙트 (side-effects)를 찾기 위함이다. 하지만, 주요 목적은 관심의 이동이다. (a shift of focus)
결함 유형은 분석될 수 있다. 가능한 분류법은 (14)에 설명되어 있다. 원칙적으로, 모든 결함은 몇몇 디자이너의 약점을 나타내는 증상이다. 그리고 이것은 동일 종류의 더 많은 결함을 찾기 위해 적극적으로 활용되어야 한다.
예제: Y2K 프로젝트에서, 2000년도의 년도 필드에 00이 나오지 않고 블랭크가 표시되는 프로그램을 발견했다. 이것에 대응되는 잘못된 코드를 가진 다른 많은 프로그램도 동일한 문제의 비슷한 양상을 보였었다.
또 다른 접근법은 좀더 일반적인 유형의 결함에 테스트를 더 집중하는 것으로, 이러한 것들이 코드 내에서 더 공통적이기 때문이다. 하지만, 문제는 테스트가 이미 이러한 종류의 결함을 더 많이 찾도록 디자인되었기 때문에 이미 그러한 결함이 발견되었을 것이라는 점이다. 충분한 분석이 필요하다. 일반적으로, 발견된 모든 결함에 추상화를 적용하여 더 테스트하거나 더 분석할 수 있는 체크리스트로 사용한다.
결함의 위치 또한 테스팅을 집중하는데 사용될 수 있다. 만일 한 영역의 코드가 특별히 실패가 많다면, 그 영역은 모든 심화 테스팅에 후보군이 되어야 한다 (7, 13). 하지만 분석 기간 동안에 높은 결함 수준을 보이는 영역이 특히 그 영역에 높은 테스트 커버리지가 적용되었기 때문은 아니라는 점에 주의한다.
5. 테스팅을 더 값싸게 수행하기
예산과 시간 소모를 줄이는 가용한 전략은 더 생산적이고 효과적인 방식으로 작업을 하는 것이다. 이것은 대개 기술 적용이 포함된다. 소프트웨어에서 기술 뿐만 아니라, 인적 능력배양도 비용을 줄이고, 효과를 증진하는 방법으로 생각된다. 이것은 테스팅에서도 적용된다.
자동화
수많은 테스트 자동화 툴이 존재한다. 툴 카탈로그는 매번 새로운 개정판의 툴을 내놓는다. 기존의 툴들은 비용을 더 지불하지 않고도 기능이 더욱더 강력해진다 (12). 아마 자동화는 테스트 실행과 리그레션 테스팅의 영역에서 가장 많이 활용될 수 있을 것이다. 경험상 더 많은 테스트 케이스들이 수동 테스팅에 쓰이는 리소스의 1/3보다 더 적으며, 더 적은 비용으로 실행될 수 있다. 추가로 자동화된 테스트는 더 많은 결함을 발견한다. 이것은 소프트웨어 품질에 좋은 일이다. 하지만, 결함 수정이 프로젝트를 지연시킬 것이므로 테스터들을 괴롭힌다. 여전히 그러한 툴들은 훈련, 초기 인프라 구축 같은 투자를 필요로 하기 때문에 널리 인기있지는 않다. 종종 그 툴과 씨름하느라 많은 비용이 소모된다. 생산성 향상을 위해, 말할것도 없이 그러한 툴의 적용은 플랫폼과 사람 그리고 조직에 매우 의존적이다. 사례들이 널리 전파되고, 어떤 프로젝트의 자동화는 커다란 효과를 보기도 한다.
자동화 없이는 거의 불가능한 테스트 영역은 스트레스, 볼륨 그리고 성능 테스팅이다. 여기에서의 질문은 자동적으로 그것을 수행하거나 아니면 아예 하지 않는 것 둘 중 하나다.
테스트 관리자는 테스트 케이스, 기능, 결함과 수정의 추적에 툴을 사용해서 상당한 효과를 볼 수 있다. 그러한 툴들은 이제 더욱더 자주 자동화 툴과 함께 사용되고 있다.
일반적으로, 자동화는 테스팅 예산을 줄이는데 관심을 둔다. 하지만, 당신이 프로젝트 외부에서 툴 평가와 도입에 대한 비용을 충당해야 하고, 당신이 관리해야 함을 명심해야 한다. 툴은 당신이 이미 그것을 어떻게 하면 효과적으로, 효율적으로 사용하는지 아는 사람일 때만 도움이 된다. 마지막에 툴을 도입하는 것은 이득의 가능성이 낮고, 좋기 보다는 해를 끼칠 수 있다.
피플 요소 - 소수의 훌륭한 사람과 잘 모르는 다수의 사람
적절한 테스팅 인력관리에 가장 큰 장애는 관리자가 가지는 무지이다. 그들중 일부는 "개발은 영리함을 필요로 하지만, 테스터는 누구라도 될 수 있다."라고 믿는다.
테스팅은 기술과 지식을 필요로 한다. 어플리케이션 지식이 없다면 당신의 테스터는 무엇을 살펴야 하는지 모를 수 있다. 당신은 아무런 결함을 찾을 수 없는 피상적인 테스트 케이스만 얻게된다. 일반적인 오류에 대한 지식이 없다면 테스터들은 어떻게 하면 훌륭한 테스트 케이스를 만들 수 있는지 모르게 된다. 훌륭한 테스트 케이스는 말하자면, 에러가 있다면 에러를 찾을 확률이 높은 것으로, "파괴적인 테스트 케이스"로 불린다. 다시 말하지만, 아무나 임명된 테스터들은 결함을 찾지 못한다. 테스트 방법론이 적용된 경험이 없다면, 사람들은 상세 테스트 계획을 실행하는데 불필요하게 많은 시간을 소모하게 될 것이다.
만일 테스팅이 적은 비용은로 수행되어야 한다면, 최선은 테스트 후보군을 수집하기 위해 매우 숙련된 소수의 스페셜리스트와 수준있는 테스터를 고용해서 문서 작성 없이 테스트를 즉석에서 하도록 하는 것이다. 능력 있는 사람들은 체크리스트를 가지고 즉석에서 동등 분할, 경계값 분석, 파괴적인 조합을 이용해 작업할 수 있다. 비숙련된 사람들은 덜 파괴적인 테스트를 수행하기 이전에 많은 양의 문서를 산출할 것이다. 이 방법은 "탐색적 테스팅"이라 불린다.
테스트 인력은 최소한 디자이너들과 동등하게 스마트하고 훌륭해야 하며, 시스템의 기능에 대한 동일한 이해를 가져야 한다. 누군가는 기능 디자인이 완료되자마자 기능 디자인 팀의 리더가 시스템 테스트 팀 리더가 되도록 할 수 있다. 프리세일즈, 문서화, 훈련, 제품 마케팅이나 고객 지원 인력 또한 테스트 팀에 포함되어야 한다. 이것은 초기에 지식의 전이 (knowledge transfer) (개발과 다른 조직 양쪽의 윈윈)가 가능하도록 해서, 기존에 가진 리소스보다 더 많은 리소스를 제공한다. 테스트 실행은 항상 있을 필요는 없는 인력을 많이 요구한다. 하지만, 소프트웨어에 대한 비평적이고 풍부한 지식을 가진 시각은 필요하다. 또한 당신은 풀 타임 테스터가 필요할 수도 있지만, 테스팅 기간중 최고 피크 기간에 필요한 양 만큼은 아닐 것이다. 풀 타임 테스트 팀 구성원은 테스트 디자인과 실행에 적합하고, 덜 바쁜 시간 동안에 인프라나 테스팅 툴의 구축과 작성에 적합하다.
만일 즉석으로 만든 테스트가 반복되어야 한다면, 문제가 있다. 하지만 현대의 테스트 자동화 툴들은 캡쳐 모드에서 작동할 수 있어서 캡쳐된 테스트가 나중에 재실행 목적과 문서화를 위해 수정될 수 있다.
메시지는 다음과 같다. 당신의 테스트 팀에 최고로 능력있는 사람을 고용하라!
6. 테스팅 작업 줄이기
비용을 줄이는 또 다른 방법은 작업의 일부분을 없애는 것이다. 누군가 다른 사람이 하도록하거나 완전히 없앤다!
누가 유닛 테스팅을 해야 하나?
종종 유닛 테스팅은 프로그래머에 의해서 수행되며, 어떤 공식적인 테스팅 예산도 할당되지 않는다. 문제는 유닛 테스팅이 종종 실제로 수행되지 않는다는 점이다. 테스트 커버리지 툴 벤더들은 종종 자신들의 툴이 없이는, 코드의 40-50%가 유닛 테스트되지 않는다고 말한다. 그러면, 많은 결함들이 이후 테스트 단계까지 살아남게 된다. 이것은 이후의 테스트 단계들이 더욱 훌륭해야 하며, 이전에 이미 찾아졌어야 했던 모든 결함을 찾아야 하기 때문에 테스터들에게 부담이 되거나 일정이 지연됨을 의미한다. (This means later test phases have to test better, and they are overloaded and delayed by finding all the defects which could have been found earlier.)
테스트 매니저로서 당신은 더 높은 수준의 유닛 테스팅을 요구해야 한다! 이것은 현대 소프트웨어 개발인 "애자일" 접근방법의 한 축이다. 유닛 테스트가 잘 자동화되어서 유닛이 변경되거나 통합될 때마다 재실행되어야 한다.
테스트 진입 조건은 어떤가?
이 아이디어는 외부 고객과의 계약과도 같다. 즉, 공급자가 계약을 만족하지 못하면, 그 공급자는 인수를 거부당하고 비용청구도 할 수 없다. 공급자가 한 명뿐이고, 품질을 요구하는 문화가 없다면 문제가 발생한다. 이 두가지 조건은 소프트웨어 분야에서 진실이다. 하지만 테스트 그룹이 충분히 강력하다면 진입 조건이 적용될 수 있다. 진입 조건 (criteria)에는 사소한 것부터 좀더 고차원적인 것까지 많은 것이 포함되는데, 여기에 테스팅을 좀더 손쉽게 해주는 몇가지 예들을 제시한다.
* 해당 시스템은 통합이나 시스템 테스트가 완료된 이후에 (고객에) 전달된다.
* 충분한 정적 분석이 이루어져와서 결함이 수정되었다.
* 코드 리뷰가 지속되어왔으며, 결함도 수정되어 왔다.
* 유닛 테스팅은 승인된 표준에 의해 이루어져왔다 (예를 들면, 거의 100%의 구문 커버리지)
* 요구된 문서는 어떤 것이든 작성되었고, 문서에 어떤 수준의 품질이 있다.
* 유닛들이 문제없이 통합되고 설치될 수 있다.
* 유닛들은 어떤 기능적인 테스트 케이스들을 통과했다 (스모크 테스트).
* 정말로 나쁜 유닛들을 골라내어서, 추가적인 리뷰나 재프로그래밍 등의 특별한 취급을 한다.
당신이 이 모든 통과 기준을 필요로 하진 않을 것이다. 또 당신이 그들에게 이것들을 강제하도록 허용되지 않을 수도 있다. 하지만, 당신은 통과 기준을 적용함으로써 시간이 지나면서 프로젝트의 상태를 개선하도록 변화시킬 수 있다. (But you may turn projects into a better state over time by applying entry criteria.) 모든 유닛이 리뷰되고 정적으로 분석되고, 유닛 테스트되면, 당신이 이후에 싸워야 할 문제들이 많이 줄어들게 될 것이다. (If every unit is reviewed, statically analyzed and unit tested, you will have a lot less problems to fight with later.)
적은 문서화
만일 하나의 테스트가 "원칙대로" 디자인되었다면, 문서화하는데 많은 작업을 필요로 할 것이다. 이 모든 것이 필요한 것은 아니다. 테스트는 고수준 언어로 작성되며, 개념적일 수 있다. 테스트 로그는 테스트 자동화 툴이 만들어주어서 생성된다. 숙련된 인력은 체크리스트로 부터 훌륭한 테스트를 만들어 낼 수 있으며, 심지어 반복도 가능하다. 당신이 필요로 할 문서를 정확하게 체크해서 더 많이 만들지 않도록 하라. 가장 중요한 것은 무엇이 반드시 테스트되어야 하는지에 대한 테스트 계획과 무엇이 수행되었는지와 잔존하는 리스크에 대한 테스트 요약 리포트이다.
설치 비용의 감소 - 결함 수정을 위한 전략
모든 결함은 테스팅을 지연시키며 추가적인 비용을 발생시킨다. 당신은 실제 테스트 케이스를 반복수행해야 하며, 결함을 재현해내려 애쓰고, 할 수 있는한 많이 문서화 하고, 아마 디자이너들의 디버깅을 도울 것이다. 그리고, 결국에는 새 버전을 설치하고 다시 재테스트 할 것이다. 이러한 추가적인 비용은 테스트 매니저가 제어하기에는 불가능하다. 왜냐하면, 이것은 전적으로 시스템의 품질에 달려있기 때문이다. (This extra cost is impossible to control for a test manager, as it is completely dependent on system quality.) 이 비용은 대개 예산으로 잡히지 않는다. 하지만 여전히 이 비용은 발생한다. 여기에 비용을 낮추는 몇가지 제안을 한다.
언제 하나의 결함이 수정되고 언제 수정되지 않는가?
한 결함의 수정에 의해 매번 설치가 이루어지는 건 번거롭다. 즉, 새 버전의 설치, 초기화, 수정에 대한 재테스팅, 전체에 대한 재 테스팅이 포함된다. 한 번에 많은 수정들을 설치함으로써 이러한 작업들은 최소화될 수 있다. 이것은 당신이 결함 수정을 기다려야 함을 의미한다. 반면에, 만일 결함 수정 그 자체가 잘못되었다면, 이 전략은 새버전의 디버깅에 더 많은 작업을 쏟아야 한다. 결함은 발견하기 쉽지 않다. 시스템의 크기에 대한 의존성과, 신규 결함이 유입될 가능성, 그리고 설치 비용에 대한 최적의 조합이 있을 것이다. 실용적인 테스트 종료 기준의 훌륭한 예는 (2)를 보라. 여기에는 결함 수정 작업을 최적화하기 위한 몇가지 지침을 제시한다.
규칙 1: 중요한 결함만 수정한다!
규칙 2: 변경 요청과 소소한 결함들은 다음번 릴리즈로 넘긴다!
규칙 3: 그룹으로 결함을 수정한다! 대개 블로킹 실패들이 발견된 이후가 적합하다.
규칙 4: 어떤 수정이라도 발생하면 곧바로 자동화된 "스모크 테스트"를 사용한다.
7. 예방을 위한 전략들
이 기고에서의 앞부분에 제시한 시나리오는 모든 것이 늦어지고, 전용 예산이 집행되지 않았던 상황이다. 대부분의 조직은, 기존의 경험 데이터가 없으며, 개발, 테스팅, 유지 보수에서의 에러 비용에 대해 실제로 추정하려는 심각한 고민이 없다. 경험적인 데이터가 없는 경우, 테스트가 감소될 때의 비용에 대해 논의할 수 있는 방법은 없다.
반드시 해야 하는것:
* 비용 계산 체계가 있어야 함
* 경험과 모델에 근거한 비용 추정을 적용해야 함
* 테스트 품질과 유지 보수의 문제가 어떤 상호관계가 있는지 알아야 함 (You need to know how test quality and maintenance trouble interact)
측정 지표 (Measure):
* 코드 라인수, 기능 점수 (function points)등에 의한 프로젝트의 크기
* 관리, 개발, 리뷰, 테스트 준비, 테스트 실행, 재작업에 사용된 작업의 퍼센티지
* 릴리즈 이후 첫 3개월 또는 6개월 동안의 재작업의 양 (Amount of rework during first three or six months after release)
* 결함 분포, 특히 유저가 발견한 문제의 원인을 중점으로
* 추가된 테스팅 비용 대비 출시 이전과 이후에 줄일 수 있는 재작업량을 측정해서 테스팅 리소스에 대해서 논의한다.
프로젝트의 경험 분석으로 비용과 이익간에 어떤 관계가 있는지를 보여주는, Otto Vinter from Bruel&Kjær에 의해 수행된 몇몇 ESSI 프로젝트에서 발표된 자료들이 있다 (6). 문제를 예방하는 또 다른 방법은 증감적인 출시 (incremental delivery)이다. 일반적인 아이디어는 수많은 작은 릴리즈들로 시스템을 나누는 것이다. 고객에게 전달하는 첫번째 릴리즈는 상업적으로 최소한도로 받아들일 수 있는 시스템이다. 말하자면, 예전 시스템이 하는 일을 그대로 하지만, 신기술이 탑재된 시스템을 말한다. 이 첫번째 버전의 테스트를 통해 당신은 비용, 에러의 내용, 나쁜 영역 등에 대해 배울 수 있다. 그리고 나서, 더 나은 계획을 짤 기회를 얻게 된다.
8. 요약
관리자들이 예산과 시간 모두를 깎으려고 하는 상황 안에서의 테스팅은 나쁜 게임 (bad game)이다. 당신은 이 게임에서 견디고 살아남아, 성공으로 이끌어야 한다. 이런 상황에서의 일반적인 방법론은 모든 영역을 조금씩 테스트 하지 않고, 오히려 가장 리스크가 높은 영역과 가장 나쁜 영역에 집중하는 것이다.
우선 순위 1: 가능한 한 심각하게 약점이 있는 부분의 목록과 함께 가능한 한 빨리 개발자들에게 제품을 돌려 보내라.
우선 순위 2: 당신이 언제 테스팅을 중단하든지 간에, 가능한 시간 내에서 최고의 테스팅이 이루어지도록 하라!
References
(1) Joachim Karlsson & Kevin Ryan, “A Cost-Value Approach for Prioritizing Requirements”, IEEE Software, Sept. 1997
(2) James Bach, “Good Enough Quality: Beyond the Buzzword”, IEEE Computer, Aug. 1997, pp. 96-98
(3) Risk-Based Testing, STLabs Report, vol. 3 no. 5 (info@stlabs.com)
(4) Sta*le Amland, "Risk Based Testing of a Large Financial Application", Proceedings of the 14th International Conference and Exposition on TESTING Computer Software, June 16-19, 1997, Washington, D.C., USA.
(5) Tagji M. Khoshgoftaar, Edward B. Allan, Robert Halstead, Gary P. Trio, Ronald M. Flass, “Using Process History to Predict Software Quality,” IEEE Computer, April 1998
(6) Several ESSI projects, about improving testing, and improving requirements quality, have been run by Otto Vinter. Contact the author at otv@delta.dk.
(7) Ytzhak Levendel, “Improving Quality with a Manufacturing Process”, IEEE Software, March 1991.
(8) “When the pursuit of quality destroys value”, by John Favaro, Testing Techniques Newsletter, May-June 1996.
(9) "Quality: How to Make It Pay," Business Week, August 8, 1994
(10) Barry W. Boehm, Software Engineering Economics, Prentice Hall, 1981
(11) Magne Jørgensen, 1994, “Empirical studies of software maintenance”, Thesis for the Dr. Scient. degree, Research Report 188, University of Oslo.
(12) Lots of test tool catalogues exist. The easiest accessible key is the Test Tool FAQ list, published regularly on Usenet newsgroup comp.software.testing. More links on the author’s
web site.
(13) T. M. Khoshgoftaar, E.B. Allan, R. Halstead, Gary P. Trio, R. M. Flass, ?Using Process History to Predict Software Quality?, IEEE Computer, April 1998
(14) IEEE Standard 1044, A Standard Classification of Software Anomalies, IEEE Computer Society.
(15) James Bach, << A framework for good enough testing >>, IEEE Computer Magazine, October 1998
(16) James Bach, "Risk Based Testing", STQE Magazine,6/1999, www.stqemagazine.com
(17) Nathan Petschenik, "Practical Priorities in System Testing", in "Software- State of the Art" by DeMarco and Lister (ed), Sept. 1985, pp.18 ff
(18) Heinrich Schettler, “Precision Testing: Risikomodell Funktionstest” (in German), to be published.
(리스크 기반 테스팅, 마감일에 맞추어 테스트 우선순위를 선정하기 위한 전략들)
Hans Schaefer, Software Test Consulting, hans.schaefer@ieee.org
http://home.c2i.net/schaefer/testing.html
종종 테스트 실행 이전의 모든 다른 활동들이 지연된다. 이것은 테스팅이 매우 심한 압력을 받으며 완료되어야 함을 의미한다. 그 일을 그만두거나, 출시 일정이 지연되거나 나쁘게 테스트 되거나 하는 것을 논외로 할때, 정답은 제한된 리소스를 가지고 최선의 가능한 일을 하기 위한 우선 순위 설정 전략이다.
시스템의 어떤 영역이 가장 많은 관심을 필요로할까? 특출난 대답은 없다. 그리고 무엇을 테스트 할 것인가에 대한 결정은 위험을 기반으로 해야 한다. 테스팅에 사용되는 리소스와 테스팅 이후의 리스크 간에는 관계가 있다. 단계별 릴리즈에 대한 가능성도 있다. 일반적인 전략은 다른 것들은 지연시키면서 릴리즈되었으면 하는 몇몇 중요한 기능들을 테스트 하는 것이다. (The general strategy is to test some important functions and features that hopefully can be released, while delaying others.)
첫째로, 누군가는 그 어플리케이션 내에서 가장 중요한 것을 테스트 해야 한다. 이것은 기능의 가시성, 사용 빈도, 실패시 발생하는 비용을 확인함으로써 결정할 수 있다. 둘째로, 누군가는 실패 가능성이 높은 부분을 테스트 해야 한다. 즉, 가장 문제가 되는 부분을 찾는 것이다. 이것은 제품 내에서 특히 결함 경향이 심한 (defect-prone) 영역을 확인함으로써 결정할 수 있다. 프로젝트 이력은 어떤 힌트를 제공할 수 있으며, 복잡도 같은 제품 측정치는 많은 힌트를 제공한다. 이 두가지를 사용해서 더 많이 테스트 해야 하는 영역과 덜 테스트 해야 하는 영역을 알아낼 수 있다.
테스트 실행이 시작되고 난 이후에, 몇개의 결함이 발견된다. 이 결함들은 아마도 re-focussing 테스팅의 근간이 될 것이다. 결함은 결함 경향이 심한 영역들에 서로 몰려있게 된다. 결함은 개발자들이 저지른 전형적인 실수들의 증상이다. 따라서, 하나의 결함은 더 많은 결함들이 근처에 존재한다는 추론을 가능케 한다. 그러므로, 동일 유형의 더 많은 결함들이 존재한다. 따라서, 테스트 실행의 후반부 동안에 누군가는 결함들이 어디에서 발견되었었는지 관심을 가져야 하며, 이전에 발견된 결함의 유형을 목표로 해서 더 많은 테스트를 만들어야 한다.
Disclaimer: 이 기고의 아이디어들은 안전 제일의 소프트웨어 (safety critical software)에서 사용되는 상황에서 검증되지 않았다. 이 아이디어들 중 일부는 그 영역에 적합할 수도 있으나, 충분한 고려가 필요하다. 여기에 제시된 아이디어들은 테스터가 리스크를 감당한다는 의미이며, 그 리스크는 심각한 실패로 현실화될 수도, 그렇지 않을 수도 있다.
소개
시나리오는 다음과 같다. 당신은 테스트 매니저이며, 당신이 테스팅에 대한 예산과 계획을 세웠다. 당신이 알고 있는 한도 내에서 당신의 계획은 합리적이며, 잘 짜여졌다. 테스트 계획을 실행할 시점이 되었을 때, 제품은 아직 준비 되지 않았고, 테스터들 또한 가용하지 않거나 예산이 방금 삭감되었다. 당신은 이러한 예산 삭감에 대해서 논쟁할 수도, 더 많은 시간이나 그게 무엇이든 간에 요구할 수 있다. 하지만, 그런 것들이 항상 도움이 되지는 않는다. 당신은 당신이 가진 더 적은 예산 더 짧은 시간을 가지고 일해야 한다. (일을) 그만 두는 것은 논쟁거리가 아니다. 당신은 일을 진행해야 할 뿐만 아니라 제품을 테스트 해야 한다. 그리고, 당신은 릴리즈 이후에도 무리없이 잘 작동하도록 만들어야 한다. 어떻게 하면 살아남을 수 있을까?
다양한 기법을 사용하고, 테스팅 프로세스의 여러 다른 측면을 공격하는 다양한 방법론이 존재한다. 이들중 일부는 제품 릴리즈 이전에 가능한한 많은 개수와 가능한 심각한 결함을 찾는 것에 목적이 있다. 이 기고의 다른 장에서 그 아이디어를 보일 것이다. 기고의 끝부분에서 어떤 아이디어가 제시되는데, 이것은 앞서 언급한 심한 압력의 시나리오를 방지하는데 도움이 될 것이다.
이 기고에서 우리는 상위 레벨의 테스팅에 대해서 이야기하고 있다. 즉, 통합, 시스템, 인수 테스트가 그것이다. 우리는 개발자들이 이미 모든 프로그램의 기본적인 수준의 테스팅을 수행해왔다고 가정한다 (유닛 테스팅). 또한 프로그램과 그 디자인이 어떤 식으로든 리뷰가 되어져왔다고 가정한다. 물론, 이 기고의 대부분의 아이디어들은 당신이 테스트 매니저를 맡기 이전에 아무것도 이루어져 있지 않더라도 가능하다. 하지만, 당신이 디자인/코드 리뷰나 유닛 테스팅 같은 앞단의 품질 제어 활동에서의 결과를 알고 있다면 더 손쉬워질 것이다. (It is, however, easier if you know some facts from earlier quality control activities such as design and code reviews and unit testing.)
1. 배드 게임
당신은 잃을 가능성이 아주 높은 게임을 하고 있다. 당신은 형편없는 테스팅을 하거나, 테스트하는데 더 많은 시간을 필요로 하게 되어 어쨌든 이 게임에서 질 것이다. 형편없는 테스팅을 한 이후에는 당신은 아마도 나쁜 품질에 대한 희생양이 될 것이다. 합리적인 테스팅을 한 이후에라도 당신은 늦은 릴리즈에 대해 책임을 질 것이다. 이러한 문제를 보여주는 좋은 시나리오는 Y2K 프로젝트이다. 마감일은 정해져 있었고, 테스팅은 아마도 마지막까지 진행되었을 것이다. 대부분의 경우, 디자인과 테스팅 동안에 문제가 발견되었고, 시스템의 소유자들은 문제가 발견된 것에 대해서 반겼을 것이다. 2000년 1월 1일에 아무런 나쁜 일도 일어나지 않았고, 이후 매니저들은 테스팅에 리소스가 낭비되었다고 결론내렸다. 하지만, 선택 가능한 옵션들이 있다. 이 기고를 통해 나는 Y2K 예제를 사용해 주요 이슈들을 보일 것이다.
어떻게 하면 이 게임에서 벗어날 수 있나?
당신에게는 창의적인 해결책이 필요하다. 말하자면 당신이 게임을 바꾸어야 하는 것이다. 당신은 당신이 가진 불가능한 책무에 대해서 경영진이 이해할 수 있는 방식으로 알려야 한다. 또 대안을 제시해야 한다. 그들에게는 출시할 수 있는 제품이 필요하지만, 또한 리스크를 이해해야할 필요도 있다.
한 가지 전략은 올바른 품질 수준을 찾는 것이다. 모든 제품이 무결점 (free of defects)일 필요는 없다. 모든 기능이 작동할 필요도 없다. 때때로 당신은 제품 품질을 낮추는 선택권도 가지고 있다. 이것은 당신이 덜 중요한 영역에 대해 테스팅을 줄이는 것을 의미한다.
또 다른 전략은 우선순위이다. 테스트는 먼저 가장 중요한 결함들을 찾아야 한다. 가장 중요하다는 것의 의미는 "가장 중요한 기능 중에서"라는 의미로, 이 기능들은 각각의 기능이 (제품이 의도된) 미션을 어떻게 지원하는지를 분석하고, 어떤 기능이 치명적인지 (critical) 또는 그렇지 않은지 점검해서 찾아낼 수 있다. 또한 당신은 많은 결함이 예상되는 곳을 더 많이 테스트 할 수 있다. 제품 내에서 가장 열악한 영역을 곧바로 찾고, 그들을 더 테스팅하면 더 많은 결함을 찾는데 도움이 될 것이다. 당신이 너무나 많은 심각한 문제들을 찾았다면, 경영진이 릴리즈를 연기하도록 자극되게 하거나, 당신에게 더 많은 시간과 리소스를 줄 것이다. 이 기고의 대부분의 내용은 가장 중요한 그리고 가장 열악한 영역의 우선순위 조합에 대한 것이 될 것이다.
세번째 전략은 일반적으로 테스팅을 더 값싸게 수행하도록 해준다. 여기서의 주요 이슈중 하나는 테스트 실행 자동화이다. 하지만 주의하라. 자동화는 특히 이전에 해보지 않았거나, 잘못 했던 경우에는 비용이 많이든다! 하지만, 경험이 있는 회사들은 수동 테스팅에 비해서 아무런 오버헤드 없이 테스트 실행 자동화를 할 수 있다.
네번째 전략은 누군가 다른 사람이 비용을 지불하도록 하는 것이다. 대개, 이 누군가 다른 사람은 고객이 된다. 당신은 문제가 많은 제품을 출시하고, 고객은 당신을 위해 결함을 찾는다. 많은 회사들이 이 방법을 적용하고 있다. 고객에게 있어 이러한 게임은 다른 대안이 없기 때문에 악몽과 같다. 하지만 이 전략이 장기간의 성공에 필요한 훌륭한 전략인지에 대해서는 논의의 여지가 있다. 따라서, 이 "다른 누군가"는 테스터가 아닌 개발자가 되어야 한다. 당신은 테스트를 수행하기 이전에 어떤 진입 조건 (certain entry criteria)을 만족하는 제품이 필요할 수도 있다. 진입 조건 (entry criteria)은 지속적으로 이루어진 어떤 형태의 리뷰, 유닛 테스팅에서의 최소한의 테스트 커버리지, 어느 정도의 신뢰성이 포함될 수 있다. (Entry criteria can include certain reviews having been done, a minimum level of test coverage in unit testing, and a certain level of reliability.) 문제는 이런 것들을 강제하도록 하기 위해서는 당신이 높은 수준의 지원을 받아야 한다는 점이다. 진입 조건은 프로젝트가 심한 압박을 받고 있거나 조직의 성숙도가 낮다면 무시되는 경향이 있다.
마지막 전략은 방지 (prevention)이다. 하지만, 이것은 테스트 매니저로서 당신이 프로젝트의 시작부터 참여하게 되는 다음번 프로젝트에서만 효과를 발휘한다.
2. 필요한 품질 수준 이해하기
소프트웨어는 거대하며, 복잡한 비즈니스 세상에 탑재된다. 품질은 그 맥락에서 고려되어야 한다 (8).
품질에 대한 무자비한 추구는 소프트웨어 제품의 기술적인 특성을 극적으로 향상시킬 수 있다. 어떤 어플리케이션들 - 의료 장치, 철도 신호 어플리케이션, 항공 네비게이션 시스템, 산업 자동화 그리고 군사 방어용 시스템 - 에서 필요로하는 특정 수준의 품질은 논의의 대상이 아니다. 하지만, 품질이 상업용 시장에서 전략적인 의사 결정을 할 때 가장 또는 유일하게 중요한 참고사항일까?
품질에 대한 고려는 기업의 장기간의 경쟁력과 재정적 상황에 가장 악영향을 끼치는 기본적인 이슈를 다루는데 적합하지 않다. 실제의 이슈는 어떤 품질이 최적의 재정적 성과를 낼 것인가 하는 문제다.
당신은 어떤 품질들과 어떤 기능들이 중요한지에 대해서 확신할 수 있어야 한다. 적은 결함이 항상 많은 이익을 의미하는 것은 아니다! 당신은 품질과 재정적 성과간에 어떤 관계가 있는 조사해야 한다. 그러한 연구의 예는 AT&T (9) 같은 회사에서 사용한 Return on Quality (ROQ) 컨셉이 해당된다. ROQ는 재정적인 성과를 향상시킬 수 있는 능력에 맞추어 미래의 품질 개선을 평가한다. 또한 가치 기반의 관리 (Value Based Management) 같은 방법론도 고려한다. 품질 그 자체를 광적으로 추구하는 것은 피한다. 따라서, 더 많은 테스팅이 항상 제품 성공에 필수조건은 아니다!
Y2K 문제의 예에서, 2000년 2월 29일에 제품의 동작이 실패할 것으로 받아들여졌을 지도 모른다. 또 19xx와 20xx의 날짜들이 뒤섞인다면, 레코드들이 잘못 소팅될 것이라 받아들여졌을 것이다. 하지만, 2000년 1월 1일 이후의 주문의 처리와 기록이 가능한 제품이 가장 크게 중요하다고 생각될 수도 있다.
3. 제품의 가장 중요하고 가장 취약한 부분에 대한 테스팅 우선순위
리스크는 제품에 의한 데미지와 데미지가 발생할 수 있는 가능성이다. 리스크를 평가하는 방법은 아래 그림 1에 설명되어 있다. 리스크 분석은 사용 중에 발생한 데미지, 사용 빈도를 평가하고, 결함 유입을 관찰해서 실패의 가능성을 판단한다.
그림 1: 결함 정의와 구조 (Risk definition and structure)
테스팅은 항상 하나의 샘플이다. 당신은 결코 모든 것을 테스트할 수 없고, 항상 더 테스트 해야할 것들을 찾을 수 있다. 따라서, 당신은 항상 무엇을 테스트 해야 할지, 무엇을 테스트 하지 않아야 할지, 무엇을 더하고 덜해야 할지 결정해야 한다. 일반적인 목표는 가장 먼저 최악의 결함들을 찾는 것이다. 즉, 릴리즈 이전에 수정되어야 할 것들이며, 가능한 한 그런 결함을 많이 발견하는 것이다.
이것은 그 결함들이 반드시 중요해야 함을 의미한다. 대부분의 시스템적인 테스트 방법 (화이트 박스 테스팅, 동등 분할, 경계값 분석, 원인 결과 그래핑 같은)의 문제는 너무나 많은 테스트 케이스가 생성된다는 점이다. 이들 중 일부는 덜 중요하다 (17). 테스트 부하를 줄이는 방법은 가장 중요한 기능적 영역과 제품의 특성을 찾는 것이다. 가능한 한 많은 결함을 찾는 것은 제품의 취약한 영역을 더 테스팅해서 개선될 수 있다. 이것은 당신이 어디서 더 많은 결함이 예상되는지 알아야 함을 의미한다.
우리가 살펴본 모든 것들을 다룰 때, 그 결과는 항상 관련된 중요도를 가진 기능과 특성의 목록이 될 것이다. 최종 분석을 가능한 한 쉽게 하기 위해서 우리는 1 부터 5까지의 단계로 요소들을 표현할 것이다. 5점은 "가장 중요함" 또는 "가장 나쁨"에 부여하며, 대개 높은 리스크를 가지며, 더 많이 테스트하기 원하는 것이다. 1점은 덜 중요한 영역에 부여한다. (다른 출판물에서는 종종 1에서 3까지의 가중치를 사용한다).
상세 계산식은 이후에 제공한다.
3.1 데미지의 결정: 무엇이 중요한가?
당신은 테스트되어야 하는 영역에서 가능한 데미지가 발생한다는 사실을 알아야 한다. 이것은 제품의 가장 중요한 영역을 분석해야 함을 의미한다. 이 섹션에서는 이것을 우선순위화하는 방법을 살펴본다. 여기에 보여진 아이디어는 절대적으로 적절한 것은 아닐 수도 있다. 모든 제품에서 더 중요한 역할을 하는 요소가 존재할 수도 있다. 하지만, 여기에 제시된 요소들은 몇몇 프로젝트들에서 가치가 있었다.
중요한 영역은 기능들이나 기능 그룹일 수도 있고, 성능, 용량, 보안성 등의 특징일 수도 있다. 이러한 분석의 결과는 기능이나 특성 또는 관심이 필요한 그 둘의 조합의 목록이다. 나는 여기서 기능들을 더 중요하고 덜 중요한 영역들로 분류하는데 집중하고 있다. 하지만, 이 접근법은 유연하며, 다른 아이템들과 조정될 수 있다.
주요 기능들은 다음과 같다.
* 치명적인 (critical) 영역들 (실패의 결과나 실패의 비용)
당신은 전체적인 환경 내에서 그 소프트웨어의 사용형태를 분석해야 한다. 그 소프트웨어가 실패할 수 있는 방법을 분석한다. 그러한 실패 모드의 가능한 결과나 최소한 최악의 결과를 찾아본다. 여분의 백업 설비나 분석가나 오퍼레이터, 유저에 의해 소프트웨어 출력을 수동으로 체크할 수 있는 방법을 고려한다. 소프트웨어가 제어하는 하나의 프로세스에 직접 연결된 소프트웨어는 사용 전에 수동으로 출력이 리뷰되는 소프트웨어보다 더 치명적이다. 만일 소프트웨어가 하나의 프로세스를 제어한다면, 이 프로세스 그 자체가 분석되어야 한다. 그 프로세스 자체의 관성과 안정성은 어떤 형태의 실패를 만들어 낼 수도 있다.
예: 텔레콤 오퍼레이터를 위한 가입자 정보 시스템은 예를 들어, 가입 만료 일자로 31-12-99와 같은 애매한 숫자를 사용하는 경우 가입자 라인을 해지할 수도 있다. 이것은 치명적인 실패이다. 반면에, 리포트에서 년도 숫자는 2000년이 되면 공백으로 출력될 수도 있으나 이것은 작은 이슈이다.
작업 기간 동안에 즉시로 필요한 출력의 경우 몇 시간이나 며칠후에 전송될 수 있는 출력보다는 더 치명적이다. 반면에, 우편으로 대량의 데이터가 잘못 전송되는 경우, 우편 재발송 비용은 끔직한 수준이다. 데미지는 아래에 언급된 분류나 금전적인 가치로 정량화되거나 더 나은 무언가에 의해서 분류될 수 있다. 대규모의 다양한 데미지를 가진 시스템에서는 절대적인 금전적인 가치로 데미지를 사용하고, 더 하위의 그룹으로 분류하지 않는 것이 좋은 방법이다.
데미지의 그룹핑을 위해 가능한 계층 구조는 다음과 같다.
실패가 재난 수준인 경우 (3)
문제가 컴퓨터를 중단 시키거나, 심지어 환경에 크래쉬를 유발할 수도 있다 (전 국토나 비즈니스, 제품이 중지됨). 이러한 실패는 대규모의 재정적 손실을 다루어야 하며, 심지어 인명의 손실까지 초래한다. 예제에서도 특정 일자에 전화 네트워크의 모든 가입자가 대량 해지될 수도 있다.
실패로 인한 사업 면허 취소가 이런 유형에 속한다. 즉, 당국이 사업을 취소시킬 수도 있다. 심각한 법적인 결과가 또한 여기에 해당된다.
재난 수준의 실패의 마지막 종류는 인명에 위협이 되는 것이다.
실패가 데미지를 주는 경우 (2)
프로그램이 중단될 수도 있거나 데이터가 망실, 손상되고 프로그램이나 컴퓨터가 재시작 될때까지 기능이 작동하지 않는다. 예로는 12월 31일 한밤중쯤에 장비가 작동하지 않는 경우이다.
실패가 방해를 유발하는 경우 (1)
유저가 회피방법을 찾도록 강제되고, 동일 결과에 도달하기 위해 더 어려운 액션을 취해야 한다.
실패가 귀찮은 경우 (0)
문제가 기능에 악영향을 주지 않으나, 제품이 유저나 고객에게 덜 만족감을 준다. 하지만, 고객은 문제를 가지고도 일을 처리할 수 있다.
* 가시적인 영역들
가시적인 영역들은 무언가 잘못될 경우 많은 유저들이 실패를 경험하게 되는 영역이다. 유저에는 터미널에 앉아있는 오퍼레이터 뿐만 아니라, 리포트, 송장 또는 그 비슷한 것, 소프트웨어가 포함된 제품에 의해 제공받는 서비스에 의존적인 것들을 보는 최종 유저도 해당된다. 이 주제에 대해서 고려해야 하는 요인은 유저의 관용이다. 즉, 어떤 문제에 대한 그들의 참을성이다. 이것은 서로 다른 품질들의 중요성과 연관된다. 위를 보라.
훈련되지 않고 순진한 유저들을 위한 소프트웨어, 특히 공공 장소에서 사용되는 소프트웨어는 유저 인터페이스에 주의를 기울여야 한다. 강건성 (Robustness) 또한 주요 관심사가 된다. 하드웨어, 산업계의 프로세스, 네트워크 등과 직접 상호작용하는 소프트웨어는 하드웨어 실패, 노이즈 있는 데이터, 타이밍 문제 등의 외부적인 효과에 대해서 취약할 수 있다. 이런 종류의 소프트웨어는 환경이 변경되는 경우에 밸리데이션, 베리피케이션 그리고 재테스팅을 통과해야 한다.
가시적인 영역의 예는 전화를 걸게 해주는 전화 스위치의 기능이다. 덜 가시적인 영역은 전화 교환 같은 가치를 더해주는 모든 서비스이다.
가시성의 또 다른 요인은 고객의 신뢰성 상실 가능성이다. 즉, 고객이 회사의 제품을 구매하지 않기 때문에 장기간의 비즈니스 손실을 유발하는 장기간의 데미지이다.
* 사용 빈도
데미지는 얼마나 자주 기능이 사용되는지에 달려있다.
어떤 기능들은 매일 사용되며, 다른 기능들은 거의 사용되지 않는다. 어떤 기능들은 많은 사람에 의해 사용되며, 어떤 것들은 소수의 유저에 의해 사용된다. 자주 사용되는 기능에 우선순위를 부여한다. 하루에 발생하는 트랜잭션의 수는 우선순위를 찾는데 도움이 되는 아이디어이다.
몇몇 영역을 제외할 수 있는 여지는 좀처럼 사용되지 않을 것같은 기능을 제외하는 것이다. 즉, 분기, 반년에 또는 1년에 한번만 사용되는 것들이다. 어떤 기능들은 릴리즈 이후 최초 사용되기 전에 테스트될 수도 있다. Y2K 테스팅에서 가용한 전략은 2000년 1월과 2월의 윤년 기능을 테스트하고, 2000년 12월과 2004년 사이동안에 다시 테스트 하는 것이었다.
종종 이러한 분석이 명백하지 않기도 하다. 예를 들어, 프로세스 제어 시스템에서 몇몇 기능은 외부에서는 보이지 않을 수 있다. 현대의 객체 지향 시스템에서 많은 수의 중앙 라이브러리가 모든 곳에 사용될 수도 있다. 이렇게 되면 전체 시스템의 디자인을 분석하는 것이 도움이 될 수도 있다.
가능한 계층 구조는 다음과 같다. (3단계로)
피할 수 없음 (3)
대부분의 유저가 평균적인 사용 세션 동안에 접촉하게되는 제품의 영역 (예를 들면, 스타트업, 프린팅, 세이브).
자주 (2)
대부분의 유저들이 결국에는 접촉하게되는 제품의 영역, 하지만 모든 사용 세션 동안에 사용되는 것은 아니다.
가끔 (1)
평균적인 유저들이 결코 방문할 수 없는 제품의 영역, 하지만 고급 또는 경험있는 사용자들은 가끔 필요로하는 기능이다.
거의 없음 (0)
대부분의 유저가 결코 방문할 수 없는 제품의 영역, 이것은 아주 예외적인 액션을 통해서만 방문할 수 있다. 하지만, 치명적인 실패는 여전히 관심 대상이다.
중요한 요구사항을 선정하는 또 다른 방법은 (1)에 설명되어 있다.
중요성은 1 부터 5까지 단계를 사용해서 분류될 수 있다. 하지만, 어떤 경우 이것은 현실적으로 다양한 단계를 나타내기에 충분치 않다. 그래서, 데미지의 비용이나 실제 사용 빈도 같은 실제 수치를 사용하는 것이 좋다.
3.2 실패 가능성: 무엇이 가장 나쁜가 (추측하건데)
가장 나쁜 영역은 가장 많은 결함을 가진 영역이다. 과제는 어디에 가장 많은 결함들이 내재되어 있는지 추정하는 것이다. 이것은 가능성이 높은 결함 생성자 (defect generator)를 분석함으로 할 수 있다. 이 섹션에서는 가장 중요한 결함 생성자들의 일부와 결함 경향 영역이 보이는 증상을 설명한다. 많은 것들이 존재하는데, 당신은 여기서 언급한 것들 외에 본인들 만의 요인들을 항상 포함해야 한다.
* 복잡한 영역
복잡도는 아마 가장 중요한 결함 생성자일 것이다. 200개 이상의 서로 다른 복잡도 측정법이 존재한다. 20년 이상 복잡도와 결함 밀도의 관계에 대한 연구가 이루어져왔다. 하지만, 지금까지 어떤 예측 가능한 측정법도 유효하지 않다. 여전히, 대부분의 복잡도 측정은 문제가 많은 영역들을 나타낼 수 있다. 예로써는 긴 모듈, 많은 변수의 사용, 복잡한 로직, 복잡한 제어 구조, 거대한 데이터 흐름, 함수의 중앙 집중식 배치, 다단계 계층구조 트리, 그리고 디자이너에 의해서 이해되는 주관적인 복잡도들이 해당된다. 이것은 당신이 복잡도의 여러 측면에 기반하여 다수의 복잡도 분석을 해야하며, 문제를 내포할 수 있는 제품의 서로 다른 영역을 찾아야 함을 의미한다.
* 변경된 영역
변경은 중요한 결함 생성자이다 (13). 한 가지 이유는 변경은 주관적으로 이해되기 쉬우며, 따라서 그 영향력을 (impact)을 충분히 분석하지 않는다는 것이다. 또 다른 이유는 변경이 시간적인 압박하에서, 분석이 완전히 완료되지 않은 채로 이루어진다는 점이다. 그 결과는 사이드이펙트 (sideeffects) 이다. 클린룸 프로세스 (Cleanroom process) 같은 현대의 시스템 디자인 방법론의 지지자들은 유닛 테스트에서의 디버깅은 품질에 도움이 되기 보다는 방해가 된다고 주장한다. 왜냐하면, 그들이 수정하는 것보다 더 많은 결함이 유입되기 때문이다.
일반적으로 변경 완료에 대한 약속이 존재해야 한다. 이것은 형상 관리 시스템 (그와 유사한 것)의 일부분이다. 당신은 변경들을 기능적인 영역별로 또는 다른 것으로 분류할 수 있고, 예외적으로 변경이 많은 영역을 찾을 수 있다. 이런 상황은 이전부터 디자인이 좋지 못했거나, 나쁜 디자인 이후에 최초 디자인이 수많은 변경에 의해 파괴되어 온 것일 수 있다.
또한 수많은 변경은 나쁘게 이루어진 분석의 증상이기도 하다 (5). 따라서, 과도하게 변경된 영역은 유저의 기대와 일치하지 않을 수도 있다.
* 새로운 기술, 솔루션, 방법론의 영향력
프로그래머들은 학습 곡선 (learning curve) 을 경험하는 새로운 툴, 방법론 그리고 기술을 사용한다. 초기에 그들이 익숙해질 때까지는 많은 결함을 만들어낼 수 있다. CASE 툴 같은 툴들이 회사에 새로 도입되거나 시장에 최초로 등장할 때는 다소간 불안정할 수 있다. 또 다른 이슈는 프로그래머에게 새로 도입되는 프로그래밍 언어나 GUI 라이브러리이다. 어떤 새로운 툴이나 기법도 문제를 야기할 수 있다. 좋은 예는 새로운 유형의 유저 인터페이스를 가진 최초 프로젝트이다. 일반적인 기능은 잘 작동할 수 있으나, 유저 인터페이스 서브시스템은 문제 투성이가 될 수 있다.
또 다른 고려해야 할 요인은 방법론과 모델의 성숙도이다. 성숙도는 이론적인 기반이나 경험적인 흔적의 힘을 의미한다 (Maturity means the strength of the theoretical basis or the empirical evidence.) 만일 소프트웨어가 유한 상태 기계 (finite state machines), 문법, 관계형 데이터 모델 같은 기존에 이미 수립되어 있는 방법을 사용한다면, 해결해야 하는 문제는 그러한 모델에 의해서 적절히 표현할 수 있어, 그 소프트웨어는 매우 안정적일 것으로 기대할 수 있다. 반면에, 방법론이나 모델이 새롭고 증명이 되지 않은 것이거나, 사용하는데 신기에 가까운 기술 (state of the art)을 요구한다면, 그 소프트웨어는 매우 불안정해질 수 있다.
대부분의 소프트웨어 비용 모델들은 방법론, 툴, 기술을 프로그래머의 경험에 맞추는 요소를 포함시킨다. 이것은 테스트 계획에 중요하며, 또 비용 추산에도 중요하다.
* 참여한 인원의 수에 의한 영향
여기에서의 아이디어는 1000마리 원숭이 신드롬이다. 한 작업에 많은 수의 사람이 참여할 수록, 의사소통에 더 큰 오버헤드가 생기고, 일이 잘못될 가능성이 높아진다. 숙련된 소수의 인력은 평균적인 수준의 능력을 가진 큰 그룹보다 더 생산적이다. (A small group of highly skilled staff is much more productive than a large group of average qualification.) COCOMO (10) 소프트웨어 비용 모델에서, 이것은 소프트웨어 크기 다음으로 가장 큰 요인이다. 이 영향력의 많은 부분은 결함을 발견하고 수정하는데 들어가는 effort로 설명될 수 있다.
상대적으로 숙련된 인력과 덜 숙련된 인력이 함께 배치된 영역은 더 훌륭한 테스팅이 필요한 영역이기도 하다.
이러한 분석을 할 때 심사숙고해야 한다. 어떤 회사에서는 (11) 가장 복잡한 영역에 최고의 인력을 투입하고, 쉬운 영역에 덜 숙련된 인력을 배치한다. 그러면, 결함 밀도는 인력의 숙련도와 참여한 인력의 수를 반영하지 않을 수도 있다. (Then, defect density may not reflect the number of people or their qualification.)
전형적인 케이스는 철저한 후속조치 없이 고용된 다수의 컨설턴트에 의해 개발된 프로그램이다. 그들은 각자 서로 완전히 다른 방식으로 작업한다. 테스팅 동안에 아마도 모든 사람이 서로 다른 날짜 포맷, 서로 다른 시간 윈도우를 사용하고 있는 것을 발견하게 될 것이다.
* 인력 교체의 영향
만일 인력이 그만둔다면, 새로운 인력이 그 일을 계속할 수 있기까지 디자인 제약사항을 배워야 한다. 모든 것이 문서화되어 있지 않다면, 몇몇 제약사항들은 신규 인력에게는 알려지지 않아 결함의 원인이 된다. 사람들 사이를 (작업으로) 중첩하는 것은 바람직하지 않다. 일반적으로, 인력이 교체된 영역은 동일 그룹의 인력으로 전체 작업을 완료한 영역보다 더 많은 결함을 보인다.
* 시간적 압박의 영향
시간적 압박은 사람들이 꽁수 (short-cuts)를 쓰도록 한다. 사람들은 점점더 작업을 완료하려고 집중한다. 그리고 종종 품질 제어 활동을 건너뛰며, 모든 것이 잘 될 것이라고 낙관적으로 생각한다. 성숙한 조직에서만 이러한 낙관론이 제어되는 것처럼 보인다.
또한 시간적인 압박은 오버타임 작업을 하도록 한다. 하지만, 연장 근무 기간에 사람들의 집중력이 저하된다는 것은 잘 알려져있다. 이것은 더 많은 것의 원인이 된다. 리뷰와 인스펙션의 적용에 있어 꽁수를 부리게 되어 결함 밀도를 극심한 수준까지 이끌수도 있다.
개발 기간 동안에 일어나는 시간적인 압박에 대한 데이터는 시간 목록, 프로젝트 미팅 시간을 연구하거나 관리자나 프로그래머와의 인터뷰를 통해서 잘 발견된다.
* 최적화가 필요한 영역
COCOMO 비용 모델은 비용 발생 요인중 하나로 장비의 부족과 네트워크 용량과 메모리를 언급한다. 문제는 최적화가 추가적인 디자인 노력을 필요로 하거나, 덜 강건한 (robust) 디자인 방법을 사용해서 작업될 수 있다는 점이다. 추가적인 디자인 노력은 결함 제거 활동으로 부터 리소스를 빼앗아 가며, 덜 강건한 디자인 방법은 더 많은 결함을 만들어 낼 수 있다.
* 이전에 많은 결함이 존재했던 영역들
결함 수정은 새로운 결함을 유도하는 변화를 만들어 낸다. 그리고 결함 경향이 있는 영역은 되풀이되는 경향이 있다. 리뷰나 유닛 그리고 서브시스템 테스팅에서 결함 경향이 있었던 영역이 시스템이 고객에게 전달되고 난 이후에도 결함 경향이 있는 영역이었다는 경험이 많다. (5)과 (7)의 연구에서 보이듯이 과거에 결함이 있었던 모듈은 미래에도 결함을 가질 가능성을 보인다. 만일 디자인과 코드 리뷰에서의 결함 통계 그리고 유닛과 서브시스템 테스팅의 통계가 존재한다면, 이후 테스트 단계를 위해 우선순위가 정해질 수 있다.
* 지리적인 분산
만일 한 프로젝트에서 함께 작업하는 사람들이 지리적으로 함께 하지 않는다면, 커뮤니케이션은 나빠질 것이다. 이것은 국지적 영역에 있더라도 사실이다. 여기에 위치가 프로젝트에 악영향을 줄 수 있는지 아닌지 평가하는데 도움된다고 증명된 아이디어들을 제시하겠다.
o 같은 건물 내에 서로 다른 층의 사무실에서 일하는 사람들은 동일 층에 위치하는 사람들만큼 잘 의사소통하지 못한다.
o 25미터 이상 떨어져 앉아있는 사람들은 충분히 의사소통하지 못한다.
o 작 업 공간 내에 공용 공간, 즉 공용 프린터나 커피 머신은 의사 소통을 개선해 준다. 서로 다른 건물에 앉아있는 사람들은 같은 건물에 있는 사람들만큼 의사소통 하지 않는다. 서로 다른 랩에 앉아있는 사람들은 같은 랩에 있는 사람보다 덜 의사소통한다. 서로 다른 국가에서 온 사람들은 문화적으로나 언어적으로 어려움을 겪을 수 있다. 만일 사람들이 서로 다른 시간대에 거주한다면, 의사 소통은 훨씬 더 어려울 것이다. 이것은 소프트웨어 개발 아웃소싱에서의 문제이다.
이론적으로, 지리적인 분산은 위험하지 않다. 위험은 예를 들어, 시스템의 공통 부분에 대해서 그들이 작업할 때, 거리가 떨어져 있는 사람들이 의사소통을 해야할 때 발생한다. 당신은 해당 소프트웨어 구조가 사람들간에 훌륭한 커뮤니케이션을 필요로 하지만, 이 인력들이 지리적으로 떨어져 있는 영역을 찾아내야 한다.
* 이전 사용 이력
만일 이전에 많은 유저들이 소프트웨어를 사용해왔다면, 활발한 유저 그룹은 새 버전을 테스팅하는데 도움이 될 수 있다. 베타 테스팅도 가능할 것이다. 완전히 새로운 시스템에 대해서는 유저 그룹이 정의될 필요가 있고, 프로토타이핑이 적용되어야 한다. 대개 완전히 새로운 기능 영역들은 요구사항이 잘 알려져 있지 않기 때문에 대단히 결함 경향이 많다.
* 내부적 요인
이러한 예에는 그 일을 이미 했던 사람을 찾거나, 다른 사람과 잘 의사소통하지 못하는 사람을 찾거나, 프로젝트에 새로 유입된 사람, 최근에 편성된 조직, 서로 간에 갈등이 있는 매니저들을 찾아 보는 것과 명성과 다른 많은 요인들이 포함된다. 기발한 생각만이 내부적인 요인들을 잘 구별하게 해준다. 메시지는 다음과 같다. 당신은 여기서 논의되어진 요인들 외에 가능한 외부적인 요인에 대해서 주의해야 한다.
* 고려되어야 하는 하나의 일반적인 요인
이 기고는 하이 레벨 테스팅에 대한 것이다. 이것 이전에 개발자들이 테스트를 한다. 개발자들이 이전에 그 소프트웨어를 어떻게 테스트 했었는지 살펴보고, 일반적으로 그들이 간과한 문제의 유형이 무엇인지 살펴보는 것이 합리적이다. 유닛 테스트의 품질을 분석하라. 이것은 테스트 케이스 선택 방법 (17)을 더욱 맞춤식으로 할 수 있도록 해준다.
이러한 요소들을 살피는 것은 테스트되어야 할 영역의 결함 밀도를 결정할 수 있다. 하지만, 이것만을 사용해서는 일반적으로 몇몇 영역에 과도하게 높은 수치를 부여하게 된다. 대개 거대한 컴포넌트는 테스트 해야 할 것들이 많다. 따라서, 수정 요소 (correction factor)가 적용되어야 하는데, 이것은 테스트되어야 할 영역의 기능적인 크기이다. 말하자면, 이 영역의 전체 가중치는 "결함 경향성 / 기능적인 볼륨"이 될 것이다. 이 요소는 초기 기능 점수 분석 (function point analysis)이나, 가능하다면 코드 라인수 카운트에서 발견될 수 있다.
그림 2: 실패 가능성 (Failure Probability)
당신이 그 프로젝트에 대해서 아무것도 알지 못하며, 모든 결함 생성자가 적용될 수 없다면 무얼 해야 하나?
테스트를 해야 한다. 먼저 러프 테스트를 통해 결함 경향이 있는 영역을 찾고, 다음 테스트는 그것들에 집중한다. 첫번째 테스트는 전체 시스템을 모두 커버해야 하나, 너무나 얕은 수준이 되어서는 안 된다. 이 테스트는 전형적인 비즈니스 시나리오만을 커버하고, 몇몇 중요한 실패 상황을 다루어야 하지만 전체 시스템을 커버하지는 않아야 한다. (It should only cover typical business scenarios and a few important failure situations, but cover all of the system.) 그런 다음, 가장 문제가 많은 영역을 찾고, 다음 번 테스팅 차수에 그 영역에 우선순위를 준다. 그 다음번 차수는 우선순위가 정해진 영역에 대해서 깊고 철저하게 테스팅한다. 이 두 단계의 접근법은 항상 적용될 수 있다. 테스팅 이전에 우선순위를 정하고 계획을 세우는 것 이외에도 이 두 단계의 접근법은 항상 적용될 수 있다. 4장에서 좀더 설명한다.
3.3 테스트 영역의 우선순위를 어떻게 계산하나?
일반적인 방법은 가중치를 부여하여 시스템의 모든 영역에 대한 가중치의 합계를 계산하는 것이다. 결과값이 가장 높은 것을 테스트한다! 모든 요소를 선정하고 상대적인 가중치를 할당한다. 당신은 이것을 매우 공을 들여해야 한다. 하지만, 이 작업은 매우 많은 시간을 소모하게 될 것이다. 대개의 경우 3개의 가중치로 충분하다. 1, 3, 10의 값을 정한다. ("아주 중요하지 않은 요인"에는 1, "중간정도의 영향력을 미치는 요인"에는 3, "아주 강한 영향력을 미치는 요인"에는 10).
모든 요인이 선정되었다면, 모든 제품 요구사항 (모든 기능, 기능적인 영역 또는 품질 특성)에 숫자를 부여한다. 더 중요한 요구사항이나 그 영역 내에서 결함 생성자로 보이는 것에는 더 많은 수치를 부여한다. 대개 1에서 3 또는 5까지의 단계가 충분하다. 숫자 부여는 직관적으로 수행될 수 있다.
한 요인에 부여하는 숫자는 그 자체의 가중치와 곱해진다. 이것은 1과 50 사이의 가중치가 부여된 숫자를 만들어 낸다. 이 가중치가 부여된 숫자들은 이후 데미지 (impact)와 에러 가능성과 더해져서 최종적으로는 곱해진다. 현실적으로 많은 직관적인 매핑이 로그급수로 늘어나는 모양을 보이기 때문에, 숫자들은 10의 곱의 모양을 따른다. 그러므로, 관련된 리스크 계산은 가능성과 데미지의 가중치 부여된 합이 계산된 것을 더해야 한다. 만일 대부분 요인의 점수들이 본질적으로 직선형을 따른다면, 리스크 계산은 가능성과 데미지 점수를 곱해야 한다. 이 방법을 사용하는 유저는 그들이 이 방법을 어떻게 사용할 것인지 정해야 한다! 이후에 가장 점수가 높은 영역에 대해서 가장 많은 테스트를 할당하는 계획이 세워진다.
예제 (서로 다른 영역의 기능적인 볼륨은 같다고 가정)
이 테이블은 "송장" 기능이 테스트 해야할 가장 중요한 기능이라고 제안하며, "주문 등록"과 주문 등록의 성능이 그 다음이다. 가장 중요한 것으로 선정된 요인은 가시성이다.
계산은 스프레드시트를 사용해서 프로그램될 수 있으므로 쉽다. 더 상세한 케이스 연구는 (4)를 참고하라. 스프레드시트는 http://home.c2i.net/schaefer/testing/riskcalc.hqx에서 얻을 수 있다. (Binhex file 파일이므로 저장하고, 압축해제해서 엑셀에서 오픈하라)
경고: 점수 할당은 직관적이므로 잘못되었을 수 있다. 따라서, 점수는 대강의 가이드라인으로의 의미만 있다. 중간과 낮은 리스크 영역과 높은 리스크 영역은 충분히 구별되어야 한다. 이것이 이 작업의 주요 책무이다. 또한 이것은 원래 목적에 필요한 것보다 더 정밀할 필요는 없다. 만일 더 정밀한 테스트 우선순위가 필요하다면, 더 수량적인 접근법이 사용되어야 한다. 특히 가능한 데미지는 그 자체의 절대값으로 사용되어야 하며, 점수로 변환되어서는 안 된다. 이 접근법은 (18)에 설명되어 있다.
4. 테스팅을 더 효과적으로 만들기
더욱 효과적인 테스트란 동일 시간안에 더 중요한 결함들을 찾는 것을 의미한다. 이것을 달성하기 위한 전략은 과거의 경험에서 배우고 테스팅에 적용하는 것이다.
먼저, 전체 테스트를 4개의 단계로 세분화해야 한다.
. test preparation
. pre-test
. main test
. after-test.
테스트 준비 (test preparation)는 테스트 할 영역, 테스트 케이스, 테스트 프로그램, 데이터베이스와 전체 테스트 환경을 준비한다. 특히, 테스트 환경에 대한 준비는 문제와 지연이 많을 수 있다. 일반적으로 프로그램 그 자체를 올바른 시스템과 데이터베이스 시스템에 인스톨하는 것은 쉽다. 문제는 종종 미들웨어에서 발생한다. 말하자면, 클라이언트가 동작하는 소프트웨어 간의 연결, 그리고 서로 다른 서버 상에서 동작하는 소프트웨어가 해당된다. 테스트 환경의 모든 측면을 충분히 구체화하는데 주의를 기울여야 하며, 테스트가 적시에 수행될 수 있도록 하기 위해 시운전 (dry runs)이 필요하다. Y2K 프로젝트에서, 1999년 이후의 머신 날짜에서 라이센스가 올바른지 확인하고, 라이센스가 머신 날짜의 재설정을 가능하게 하는지에 집중했었다. 집중한 또 다른 영역은 소프트웨어가 Y2K 호환이 되는지 였다.
프리 테스트 (pre-test)는 테스트 중인 소프트웨어가 테스트 랩에 설치되고 난 이후에 수행된다. 이 테스트는 일상적인 사용 시나리오를 구동하는 몇개의 테스트 케이스로 구성된다. 목표는 소프트웨어 전체가 테스팅 되기에 적합한지 또는 완전히 믿을 수 없는지, 불완전하게 설치되었는지 확인하기 위한 테스트이다. 또 다른 목표는 초기 품질 데이터를 확보하는 것으로, 이러한 데이터에는 이후 테스트를 지속하면서 집중해야 하는 결함 경향이 있는 영역을 찾는 것이다.
메인 테스트 (main test)는 사전 정의된 테스트 케이스 전체로 구성된다. 이들이 실행되면서 실패들이 기록되고, 발견된 결함이 수정된다. 그리고 테스트 랩에 새로운 소프트웨어가 설치된다. 모든 신규 설치에는 새로운 프리 테스트가 포함된다. 메인 테스트는 테스트 실행 프로젝트 동안에 대부분의 시간을 소모한다.
애프터 테스트 (after-test)는 매 소프트웨어 신규 릴리즈를 가지고 시작한다. 이것은 최적화가 발생해야 하는 단계이다. 애프터 테스트의 일부분은 리그레션 테스팅으로, 결함 수정의 사이드이펙트 (side-effects)를 찾기 위함이다. 하지만, 주요 목적은 관심의 이동이다. (a shift of focus)
결함 유형은 분석될 수 있다. 가능한 분류법은 (14)에 설명되어 있다. 원칙적으로, 모든 결함은 몇몇 디자이너의 약점을 나타내는 증상이다. 그리고 이것은 동일 종류의 더 많은 결함을 찾기 위해 적극적으로 활용되어야 한다.
예제: Y2K 프로젝트에서, 2000년도의 년도 필드에 00이 나오지 않고 블랭크가 표시되는 프로그램을 발견했다. 이것에 대응되는 잘못된 코드를 가진 다른 많은 프로그램도 동일한 문제의 비슷한 양상을 보였었다.
또 다른 접근법은 좀더 일반적인 유형의 결함에 테스트를 더 집중하는 것으로, 이러한 것들이 코드 내에서 더 공통적이기 때문이다. 하지만, 문제는 테스트가 이미 이러한 종류의 결함을 더 많이 찾도록 디자인되었기 때문에 이미 그러한 결함이 발견되었을 것이라는 점이다. 충분한 분석이 필요하다. 일반적으로, 발견된 모든 결함에 추상화를 적용하여 더 테스트하거나 더 분석할 수 있는 체크리스트로 사용한다.
결함의 위치 또한 테스팅을 집중하는데 사용될 수 있다. 만일 한 영역의 코드가 특별히 실패가 많다면, 그 영역은 모든 심화 테스팅에 후보군이 되어야 한다 (7, 13). 하지만 분석 기간 동안에 높은 결함 수준을 보이는 영역이 특히 그 영역에 높은 테스트 커버리지가 적용되었기 때문은 아니라는 점에 주의한다.
5. 테스팅을 더 값싸게 수행하기
예산과 시간 소모를 줄이는 가용한 전략은 더 생산적이고 효과적인 방식으로 작업을 하는 것이다. 이것은 대개 기술 적용이 포함된다. 소프트웨어에서 기술 뿐만 아니라, 인적 능력배양도 비용을 줄이고, 효과를 증진하는 방법으로 생각된다. 이것은 테스팅에서도 적용된다.
자동화
수많은 테스트 자동화 툴이 존재한다. 툴 카탈로그는 매번 새로운 개정판의 툴을 내놓는다. 기존의 툴들은 비용을 더 지불하지 않고도 기능이 더욱더 강력해진다 (12). 아마 자동화는 테스트 실행과 리그레션 테스팅의 영역에서 가장 많이 활용될 수 있을 것이다. 경험상 더 많은 테스트 케이스들이 수동 테스팅에 쓰이는 리소스의 1/3보다 더 적으며, 더 적은 비용으로 실행될 수 있다. 추가로 자동화된 테스트는 더 많은 결함을 발견한다. 이것은 소프트웨어 품질에 좋은 일이다. 하지만, 결함 수정이 프로젝트를 지연시킬 것이므로 테스터들을 괴롭힌다. 여전히 그러한 툴들은 훈련, 초기 인프라 구축 같은 투자를 필요로 하기 때문에 널리 인기있지는 않다. 종종 그 툴과 씨름하느라 많은 비용이 소모된다. 생산성 향상을 위해, 말할것도 없이 그러한 툴의 적용은 플랫폼과 사람 그리고 조직에 매우 의존적이다. 사례들이 널리 전파되고, 어떤 프로젝트의 자동화는 커다란 효과를 보기도 한다.
자동화 없이는 거의 불가능한 테스트 영역은 스트레스, 볼륨 그리고 성능 테스팅이다. 여기에서의 질문은 자동적으로 그것을 수행하거나 아니면 아예 하지 않는 것 둘 중 하나다.
테스트 관리자는 테스트 케이스, 기능, 결함과 수정의 추적에 툴을 사용해서 상당한 효과를 볼 수 있다. 그러한 툴들은 이제 더욱더 자주 자동화 툴과 함께 사용되고 있다.
일반적으로, 자동화는 테스팅 예산을 줄이는데 관심을 둔다. 하지만, 당신이 프로젝트 외부에서 툴 평가와 도입에 대한 비용을 충당해야 하고, 당신이 관리해야 함을 명심해야 한다. 툴은 당신이 이미 그것을 어떻게 하면 효과적으로, 효율적으로 사용하는지 아는 사람일 때만 도움이 된다. 마지막에 툴을 도입하는 것은 이득의 가능성이 낮고, 좋기 보다는 해를 끼칠 수 있다.
피플 요소 - 소수의 훌륭한 사람과 잘 모르는 다수의 사람
적절한 테스팅 인력관리에 가장 큰 장애는 관리자가 가지는 무지이다. 그들중 일부는 "개발은 영리함을 필요로 하지만, 테스터는 누구라도 될 수 있다."라고 믿는다.
테스팅은 기술과 지식을 필요로 한다. 어플리케이션 지식이 없다면 당신의 테스터는 무엇을 살펴야 하는지 모를 수 있다. 당신은 아무런 결함을 찾을 수 없는 피상적인 테스트 케이스만 얻게된다. 일반적인 오류에 대한 지식이 없다면 테스터들은 어떻게 하면 훌륭한 테스트 케이스를 만들 수 있는지 모르게 된다. 훌륭한 테스트 케이스는 말하자면, 에러가 있다면 에러를 찾을 확률이 높은 것으로, "파괴적인 테스트 케이스"로 불린다. 다시 말하지만, 아무나 임명된 테스터들은 결함을 찾지 못한다. 테스트 방법론이 적용된 경험이 없다면, 사람들은 상세 테스트 계획을 실행하는데 불필요하게 많은 시간을 소모하게 될 것이다.
만일 테스팅이 적은 비용은로 수행되어야 한다면, 최선은 테스트 후보군을 수집하기 위해 매우 숙련된 소수의 스페셜리스트와 수준있는 테스터를 고용해서 문서 작성 없이 테스트를 즉석에서 하도록 하는 것이다. 능력 있는 사람들은 체크리스트를 가지고 즉석에서 동등 분할, 경계값 분석, 파괴적인 조합을 이용해 작업할 수 있다. 비숙련된 사람들은 덜 파괴적인 테스트를 수행하기 이전에 많은 양의 문서를 산출할 것이다. 이 방법은 "탐색적 테스팅"이라 불린다.
테스트 인력은 최소한 디자이너들과 동등하게 스마트하고 훌륭해야 하며, 시스템의 기능에 대한 동일한 이해를 가져야 한다. 누군가는 기능 디자인이 완료되자마자 기능 디자인 팀의 리더가 시스템 테스트 팀 리더가 되도록 할 수 있다. 프리세일즈, 문서화, 훈련, 제품 마케팅이나 고객 지원 인력 또한 테스트 팀에 포함되어야 한다. 이것은 초기에 지식의 전이 (knowledge transfer) (개발과 다른 조직 양쪽의 윈윈)가 가능하도록 해서, 기존에 가진 리소스보다 더 많은 리소스를 제공한다. 테스트 실행은 항상 있을 필요는 없는 인력을 많이 요구한다. 하지만, 소프트웨어에 대한 비평적이고 풍부한 지식을 가진 시각은 필요하다. 또한 당신은 풀 타임 테스터가 필요할 수도 있지만, 테스팅 기간중 최고 피크 기간에 필요한 양 만큼은 아닐 것이다. 풀 타임 테스트 팀 구성원은 테스트 디자인과 실행에 적합하고, 덜 바쁜 시간 동안에 인프라나 테스팅 툴의 구축과 작성에 적합하다.
만일 즉석으로 만든 테스트가 반복되어야 한다면, 문제가 있다. 하지만 현대의 테스트 자동화 툴들은 캡쳐 모드에서 작동할 수 있어서 캡쳐된 테스트가 나중에 재실행 목적과 문서화를 위해 수정될 수 있다.
메시지는 다음과 같다. 당신의 테스트 팀에 최고로 능력있는 사람을 고용하라!
6. 테스팅 작업 줄이기
비용을 줄이는 또 다른 방법은 작업의 일부분을 없애는 것이다. 누군가 다른 사람이 하도록하거나 완전히 없앤다!
누가 유닛 테스팅을 해야 하나?
종종 유닛 테스팅은 프로그래머에 의해서 수행되며, 어떤 공식적인 테스팅 예산도 할당되지 않는다. 문제는 유닛 테스팅이 종종 실제로 수행되지 않는다는 점이다. 테스트 커버리지 툴 벤더들은 종종 자신들의 툴이 없이는, 코드의 40-50%가 유닛 테스트되지 않는다고 말한다. 그러면, 많은 결함들이 이후 테스트 단계까지 살아남게 된다. 이것은 이후의 테스트 단계들이 더욱 훌륭해야 하며, 이전에 이미 찾아졌어야 했던 모든 결함을 찾아야 하기 때문에 테스터들에게 부담이 되거나 일정이 지연됨을 의미한다. (This means later test phases have to test better, and they are overloaded and delayed by finding all the defects which could have been found earlier.)
테스트 매니저로서 당신은 더 높은 수준의 유닛 테스팅을 요구해야 한다! 이것은 현대 소프트웨어 개발인 "애자일" 접근방법의 한 축이다. 유닛 테스트가 잘 자동화되어서 유닛이 변경되거나 통합될 때마다 재실행되어야 한다.
테스트 진입 조건은 어떤가?
이 아이디어는 외부 고객과의 계약과도 같다. 즉, 공급자가 계약을 만족하지 못하면, 그 공급자는 인수를 거부당하고 비용청구도 할 수 없다. 공급자가 한 명뿐이고, 품질을 요구하는 문화가 없다면 문제가 발생한다. 이 두가지 조건은 소프트웨어 분야에서 진실이다. 하지만 테스트 그룹이 충분히 강력하다면 진입 조건이 적용될 수 있다. 진입 조건 (criteria)에는 사소한 것부터 좀더 고차원적인 것까지 많은 것이 포함되는데, 여기에 테스팅을 좀더 손쉽게 해주는 몇가지 예들을 제시한다.
* 해당 시스템은 통합이나 시스템 테스트가 완료된 이후에 (고객에) 전달된다.
* 충분한 정적 분석이 이루어져와서 결함이 수정되었다.
* 코드 리뷰가 지속되어왔으며, 결함도 수정되어 왔다.
* 유닛 테스팅은 승인된 표준에 의해 이루어져왔다 (예를 들면, 거의 100%의 구문 커버리지)
* 요구된 문서는 어떤 것이든 작성되었고, 문서에 어떤 수준의 품질이 있다.
* 유닛들이 문제없이 통합되고 설치될 수 있다.
* 유닛들은 어떤 기능적인 테스트 케이스들을 통과했다 (스모크 테스트).
* 정말로 나쁜 유닛들을 골라내어서, 추가적인 리뷰나 재프로그래밍 등의 특별한 취급을 한다.
당신이 이 모든 통과 기준을 필요로 하진 않을 것이다. 또 당신이 그들에게 이것들을 강제하도록 허용되지 않을 수도 있다. 하지만, 당신은 통과 기준을 적용함으로써 시간이 지나면서 프로젝트의 상태를 개선하도록 변화시킬 수 있다. (But you may turn projects into a better state over time by applying entry criteria.) 모든 유닛이 리뷰되고 정적으로 분석되고, 유닛 테스트되면, 당신이 이후에 싸워야 할 문제들이 많이 줄어들게 될 것이다. (If every unit is reviewed, statically analyzed and unit tested, you will have a lot less problems to fight with later.)
적은 문서화
만일 하나의 테스트가 "원칙대로" 디자인되었다면, 문서화하는데 많은 작업을 필요로 할 것이다. 이 모든 것이 필요한 것은 아니다. 테스트는 고수준 언어로 작성되며, 개념적일 수 있다. 테스트 로그는 테스트 자동화 툴이 만들어주어서 생성된다. 숙련된 인력은 체크리스트로 부터 훌륭한 테스트를 만들어 낼 수 있으며, 심지어 반복도 가능하다. 당신이 필요로 할 문서를 정확하게 체크해서 더 많이 만들지 않도록 하라. 가장 중요한 것은 무엇이 반드시 테스트되어야 하는지에 대한 테스트 계획과 무엇이 수행되었는지와 잔존하는 리스크에 대한 테스트 요약 리포트이다.
설치 비용의 감소 - 결함 수정을 위한 전략
모든 결함은 테스팅을 지연시키며 추가적인 비용을 발생시킨다. 당신은 실제 테스트 케이스를 반복수행해야 하며, 결함을 재현해내려 애쓰고, 할 수 있는한 많이 문서화 하고, 아마 디자이너들의 디버깅을 도울 것이다. 그리고, 결국에는 새 버전을 설치하고 다시 재테스트 할 것이다. 이러한 추가적인 비용은 테스트 매니저가 제어하기에는 불가능하다. 왜냐하면, 이것은 전적으로 시스템의 품질에 달려있기 때문이다. (This extra cost is impossible to control for a test manager, as it is completely dependent on system quality.) 이 비용은 대개 예산으로 잡히지 않는다. 하지만 여전히 이 비용은 발생한다. 여기에 비용을 낮추는 몇가지 제안을 한다.
언제 하나의 결함이 수정되고 언제 수정되지 않는가?
한 결함의 수정에 의해 매번 설치가 이루어지는 건 번거롭다. 즉, 새 버전의 설치, 초기화, 수정에 대한 재테스팅, 전체에 대한 재 테스팅이 포함된다. 한 번에 많은 수정들을 설치함으로써 이러한 작업들은 최소화될 수 있다. 이것은 당신이 결함 수정을 기다려야 함을 의미한다. 반면에, 만일 결함 수정 그 자체가 잘못되었다면, 이 전략은 새버전의 디버깅에 더 많은 작업을 쏟아야 한다. 결함은 발견하기 쉽지 않다. 시스템의 크기에 대한 의존성과, 신규 결함이 유입될 가능성, 그리고 설치 비용에 대한 최적의 조합이 있을 것이다. 실용적인 테스트 종료 기준의 훌륭한 예는 (2)를 보라. 여기에는 결함 수정 작업을 최적화하기 위한 몇가지 지침을 제시한다.
규칙 1: 중요한 결함만 수정한다!
규칙 2: 변경 요청과 소소한 결함들은 다음번 릴리즈로 넘긴다!
규칙 3: 그룹으로 결함을 수정한다! 대개 블로킹 실패들이 발견된 이후가 적합하다.
규칙 4: 어떤 수정이라도 발생하면 곧바로 자동화된 "스모크 테스트"를 사용한다.
7. 예방을 위한 전략들
이 기고에서의 앞부분에 제시한 시나리오는 모든 것이 늦어지고, 전용 예산이 집행되지 않았던 상황이다. 대부분의 조직은, 기존의 경험 데이터가 없으며, 개발, 테스팅, 유지 보수에서의 에러 비용에 대해 실제로 추정하려는 심각한 고민이 없다. 경험적인 데이터가 없는 경우, 테스트가 감소될 때의 비용에 대해 논의할 수 있는 방법은 없다.
반드시 해야 하는것:
* 비용 계산 체계가 있어야 함
* 경험과 모델에 근거한 비용 추정을 적용해야 함
* 테스트 품질과 유지 보수의 문제가 어떤 상호관계가 있는지 알아야 함 (You need to know how test quality and maintenance trouble interact)
측정 지표 (Measure):
* 코드 라인수, 기능 점수 (function points)등에 의한 프로젝트의 크기
* 관리, 개발, 리뷰, 테스트 준비, 테스트 실행, 재작업에 사용된 작업의 퍼센티지
* 릴리즈 이후 첫 3개월 또는 6개월 동안의 재작업의 양 (Amount of rework during first three or six months after release)
* 결함 분포, 특히 유저가 발견한 문제의 원인을 중점으로
* 추가된 테스팅 비용 대비 출시 이전과 이후에 줄일 수 있는 재작업량을 측정해서 테스팅 리소스에 대해서 논의한다.
프로젝트의 경험 분석으로 비용과 이익간에 어떤 관계가 있는지를 보여주는, Otto Vinter from Bruel&Kjær에 의해 수행된 몇몇 ESSI 프로젝트에서 발표된 자료들이 있다 (6). 문제를 예방하는 또 다른 방법은 증감적인 출시 (incremental delivery)이다. 일반적인 아이디어는 수많은 작은 릴리즈들로 시스템을 나누는 것이다. 고객에게 전달하는 첫번째 릴리즈는 상업적으로 최소한도로 받아들일 수 있는 시스템이다. 말하자면, 예전 시스템이 하는 일을 그대로 하지만, 신기술이 탑재된 시스템을 말한다. 이 첫번째 버전의 테스트를 통해 당신은 비용, 에러의 내용, 나쁜 영역 등에 대해 배울 수 있다. 그리고 나서, 더 나은 계획을 짤 기회를 얻게 된다.
8. 요약
관리자들이 예산과 시간 모두를 깎으려고 하는 상황 안에서의 테스팅은 나쁜 게임 (bad game)이다. 당신은 이 게임에서 견디고 살아남아, 성공으로 이끌어야 한다. 이런 상황에서의 일반적인 방법론은 모든 영역을 조금씩 테스트 하지 않고, 오히려 가장 리스크가 높은 영역과 가장 나쁜 영역에 집중하는 것이다.
우선 순위 1: 가능한 한 심각하게 약점이 있는 부분의 목록과 함께 가능한 한 빨리 개발자들에게 제품을 돌려 보내라.
우선 순위 2: 당신이 언제 테스팅을 중단하든지 간에, 가능한 시간 내에서 최고의 테스팅이 이루어지도록 하라!
References
(1) Joachim Karlsson & Kevin Ryan, “A Cost-Value Approach for Prioritizing Requirements”, IEEE Software, Sept. 1997
(2) James Bach, “Good Enough Quality: Beyond the Buzzword”, IEEE Computer, Aug. 1997, pp. 96-98
(3) Risk-Based Testing, STLabs Report, vol. 3 no. 5 (info@stlabs.com)
(4) Sta*le Amland, "Risk Based Testing of a Large Financial Application", Proceedings of the 14th International Conference and Exposition on TESTING Computer Software, June 16-19, 1997, Washington, D.C., USA.
(5) Tagji M. Khoshgoftaar, Edward B. Allan, Robert Halstead, Gary P. Trio, Ronald M. Flass, “Using Process History to Predict Software Quality,” IEEE Computer, April 1998
(6) Several ESSI projects, about improving testing, and improving requirements quality, have been run by Otto Vinter. Contact the author at otv@delta.dk.
(7) Ytzhak Levendel, “Improving Quality with a Manufacturing Process”, IEEE Software, March 1991.
(8) “When the pursuit of quality destroys value”, by John Favaro, Testing Techniques Newsletter, May-June 1996.
(9) "Quality: How to Make It Pay," Business Week, August 8, 1994
(10) Barry W. Boehm, Software Engineering Economics, Prentice Hall, 1981
(11) Magne Jørgensen, 1994, “Empirical studies of software maintenance”, Thesis for the Dr. Scient. degree, Research Report 188, University of Oslo.
(12) Lots of test tool catalogues exist. The easiest accessible key is the Test Tool FAQ list, published regularly on Usenet newsgroup comp.software.testing. More links on the author’s
web site.
(13) T. M. Khoshgoftaar, E.B. Allan, R. Halstead, Gary P. Trio, R. M. Flass, ?Using Process History to Predict Software Quality?, IEEE Computer, April 1998
(14) IEEE Standard 1044, A Standard Classification of Software Anomalies, IEEE Computer Society.
(15) James Bach, << A framework for good enough testing >>, IEEE Computer Magazine, October 1998
(16) James Bach, "Risk Based Testing", STQE Magazine,6/1999, www.stqemagazine.com
(17) Nathan Petschenik, "Practical Priorities in System Testing", in "Software- State of the Art" by DeMarco and Lister (ed), Sept. 1985, pp.18 ff
(18) Heinrich Schettler, “Precision Testing: Risikomodell Funktionstest” (in German), to be published.
